
There’s a short comment by Andrea Saltelli in Nature Communications on Statistical versus Mathematical Modelling. The general premise is that, like statistics, there is also a crisis in mathematical modelling. However, there isn’t the same sense of crisis about mathematical modelling as there is about statistical modelling. He thinks something can be learned by comparing the two and that [s]ociology of quantification and post-normal science can help.
I do, however, have a number of issue with the article. Firstly, I think it over-simplifies, or possibly even misrepresents, the crisis in statistics. It’s not really a crisis in statistics, it’s a problem with how some use statistics. It’s also not a problem that exists in all research areas; it’s predominantly in areas that have relied on null-hypothesis testing. There are – as far as I’m aware – many research areas where this really hasn’t been a major problem.
The other problem I have is that it seems to treat mathematical modelling as if it’s homogeneous, both in terms of how the models are developed and in terms of the model relevance. However, there is a vast difference between physical models and economic models. Mathematical models are also used for many different reasons. It can vary from theoretical studies aimed at understanding some physical system, to models used to interpret some dataset, through to models used to explicitly inform decision making. There may well be cases where the limitations of a model is not made clear, but this doesn’t imply some kind of general crisis in mathematical modelling.
This is not to say that I don’t think there aren’t any problems. There are certainly cases where people use models in ways that aren’t suitable, or use the results of a model without understanding the limitations of that model, or the significance of the assumptions that were used. I think it would be useful if there were a better understanding of the different types of models, the strengths and limitations of the various types of models, and how we should probably be utilising model results when informing decision making. I don’t, however, think that generalising about mathematical models is particularly helpful.
I also find these kind of commentaries somewhat ironic. In many cases, the problem isn’t really with the statistical method, or with the mathematical model, but with how it’s being used, or how it’s being presented. In my view, it’s important to understand when one can use a satistical method/mathematical model, be clear about the assumptions used, and be clear about the limitations and strengths of the model/method. Yet, this seems to be essentially what these commentaries lack; they present simplistic generalisations, aren’t particularly careful about their terminology, and don’t seem to be clear about the strengths and limitations of what they’re suggesting.
If there is a group of researchers who think that they’re in a position to critique the research conduct of others, you would hope that their own research satisfied this ideal. My impression, however, is that it doesn’t. If anything, I’m not even sure that some of this even really qualifies as research; it just seems to be someone’s opinion about a topic that they don’t even seem to understand all that well. I don’t think there is anything wrong with critiquing the research done by others, but doing so doesn’t mean that one is somehow immune from criticism.

As you point out, the problem with discussions like Saltelli’s is the overgeneralization of an issue. Modeling can range from “Does a process cause an impact in the same direction as the observation?”, to “How few processes will adequately describe an observed trend?” to trying to develop a fine-scale visualization of the actual changes that happened and then extrapolating those changes.
It doesn’t do anyone any good to argue that because one can define bad models then all models are bad.
Mitch,
Indeed. It’s somewhat ironic that an article about poor statistics appears to make an argument that is essentially itself based on poor statistics.
I thought statistical modelling was a branch of mathematics:
https://en.wikipedia.org/wiki/Mathematical_statistics
P. F. Cragmile, “The role of Statistics in climate research“, CHANCE, 2017
CHANCE special issue on climate
It’s arguable that no proper scientific method can disregard the successful critiques which Bayesian statistics has brought to conventional, early 20th century inferential methods. But, moreover, because many scientists act as if they believe the statistics they learned in school suffice for all future applications, they don’t read modern literature there, or even literature of fields, like quantitative Biology, or astrostatistics, where the embrace of the Bayesian approach is complete. Worse, even if they don’t like Bayes — which usually is based upon some misunderstanding of the role of Bayesian priors — there are major revolutions in Statistics which bear on their work. Possibly the most important is Stein’s paradox. A recent overview is availble.
With Stein, James-Stein estimators came on the scene (see also Stein’s lemma, along with the concept of shrinkage. And, I’d say, that’s the route to hierarchical models, principally practiced in a Bayesian setting, where an hierarchy of statistical relationships among parameters to be estimated is constructed, based upon knowledge from the problem space, and that hierarchy is used to borrow strength.
There are papers about these techniques and climate or geophysics which show up in those literatures and certainly in statistics literature. (Schmittner, Urban, Shakun, Mahowald, Clark, Bartlein, Mix, and Rosell-Mele, 2011, is a notable one) But the methodology is generally ignored by others.
As far as mathematical modeling goes, that’s pretty much my world, although I’d say I practice almost exclusively in numerical linear algebra and non-linear optimization. I have to disagree with Saltelli because I don’t see a “crisis”. I do see crappy work. I appreciate the need to make approximations to keep run times reasonable. But error analysis, both analytical and empirical, is as key now as it has ever been. I know it’s difficult with complicated models, where pieces have been lashed together. But that’s a quantitative software development problem, and there are means of handling that, the best being a cascade of models of ever increasing complexity, starting with pencil-and-paper, and demanding that the full up model at every stage comply with what the others mean.
“Emergent, ab initio physics?” Well, yeah, maybe, But I don’t/wouldn’t trust it. In that case the model itself becomes the object of study, very much as big neural network mechanisms are in Machine Learning.
ecoquant,
Exactly.
> It’s not really a crisis in statistics, it’s a problem with how some use statistics.
Yup.
It’s a crisis s opposed to what? As opposed to not using statistics?
I find this whole “crisis” framing (in a variety of contexts) problematic. It’s like saying there’s a crises in climate science because, putatively, some papers have some methodological problems. Yes, when people conduct research there can be problems. What is the alternative? Is not conducting research the alternative? So if people stop doing research, the crisis has been averted?
Science is an imperfect process. Statistical analysis is an imperfect process. Over time, people learn and hopefully make corrections. On what basis is it determined that the existence of problems is a “crisis.”
Binary thinking is…binary.
Joshua,
Indeed. It seems to me that part of the crisis in statistics is simply researchers learning about the limitations of their methods and (slowly, maybe) adapting accordingly. This doesn’t mean that it couldn’t have been better, but research methods are always evolving and this is (mostly) just a part of the whole process.
The main problem with statistics is that too many practitioners (e.g. scientists) want to treat it as a cookbook containing the recipies that they can use without taking the effort to understand the framework and principles. This leads to making errors, such as the p-value falacy and not realising that you are applying the wrong recipe (e.g. Douglass et al – of course it helps if you don’t arrogantly dismiss the advice of statisticians that try to explain the error to you – thinking of no Christys in particular ;o).
Framing things as a crisis is probably better for attracting attention to your work on the subject than just pointing out that there are problems.
One main critique in the paper is that sensitivity testing is not performed or if it is done it’s flawed. That’s true in many fields of fluids modeling and is a serious issue. It means that credible uncertainty estimation is completely absent and the model is inadequate for policy use. Figure 1 in the paper seems to me to be a great insight. More complex models become more ill posed and error propagation more pronounced. The “more physics must be better” myth betrays mathematical ignorance but is very widely believed. The figure is quite a. good one.
The other main point of the paper is about the importance of auditing models. This is usually absent and is another excellent critique. In fact even validation of new models is often absent. You are lucky if verification is completed.
dpy,
Why am I not surprised that you appear to like the article? I think you’re making the same mistake that Saltelli makes. You seem to think that there is one way in which numerical/mathematical models should be used. My point is that it’s not that simple.
I just realized there’s an article in that CHANCE magazine issue, quite pertinent to some of this:
Dorit Hammerling (2017) Climate Change Detection and Attribution: Letting Go of the Null?, CHANCE, 30:4, 26-29, DOI: 10.1080/09332480.2017.1406756
Yes ATTP, there is qualitative understanding often called “understanding the physics.” For policy quantitative information with uncertainty is vastly preferable. True in medicine and in fluids. Without uncertainty estimates I don’t see how to be confident in any “understanding” you might think you find. My experience is that these “understanding the physics” conclusions aren’t useful because you don’t know the size of the effect or how sensitive it is to modeling details in a simulation where rigorous estimation of sensitivity is impossible. If the adjoins diverges, classical error estimation fails.
> That’s true in many fields of fluids modeling and is a serious issue.
Not sure how many fields of fluids modeling there is. Speaking of which:
https://twitter.com/johncarlosbaez/status/1167446698181836800
This seems to undermine Andrea’s claim about mathematical modelling.
“It’s also not a problem that exists in all research areas; it’s predominantly in areas that have relied on null-hypothesis testing. There are – as far as I’m aware – many research areas where this really hasn’t been a major problem.”
This does not say, but suggests that Null-hypothesis testing is the problem. My impression is that the problem is for fields without much theory (a-priory humans respond in almost any way) and small sample sizes (because collecting data is expensive).
I would be surprised if the use of Bayesian statistics in psychology would have averted their replication crisis.
@Victor Venema,
Actually, you don’t have to merely wonder about this …
Etz A, Vandekerckhove J (2016) A Bayesian Perspective on the Reproducibility Project: Psychology. PLoS ONE 11(2): e0149794. https://doi.org/10.1371/journal.pone.0149794
Bayesian inference can be more difficult to set up and do than “classical inference”, but, if that’s accepted, a number of benefits arise:
Also, in most studies, correction for multiple comparisons (Bonferroni, family-wise error rates, etc) occurs automatically with the Bayesian approach, as long as one is content with calculating a posterior density in the final. There is some discussion here if one doesn’t.
There are some aspects of statistical practice with which Bayes doesn’t much help: Survey sampling and weighting is a bit of a mess. However, progress is being made.
Oh, and this reports how take-up of Bayesian methods in Psychology is progressing.
This is my opinion on reading the article yesterday:
crappy work is not a crisis.
is crappy work a catastrophy?
just asking questions.
“I find this whole “crisis” framing (in a variety of contexts) problematic.”
tell greta.
@Steven Mosher,
“Crappy work is not a crisis.”
Sure. But it is not acceptable, definitely, to the degree that people trot out “results” based upon such crappy work to the otherwise uninformed public, who cannot, by training, discern that it is indeed crap, and yet assign it some level of veracity.
Frankly, of all the XR-style impeding demonstrations out there, I find Greta’s message to be the most coherent, both in terms of respect of the Science, and in terms of assigning responsibility for the present crisis. After all, the politicians and the bureaucrats are beholden to the complaints of the general public. And, in the OECD countries at least, and certainly in the USA, people feel priviliged enough to challenge these ideas, including the entitlement notion that the government ought to defend them from poor choices regarding siting of coastal ownership.
Victor,
Yes, I agree. There is nothing fundamentally wrong with null-hypothesis testing.
dpy,
Why would you think understand the physics is qualitative, rather than quantitative? In my experience, the point is that you can use some basic physics to sanity check a model. For example, how well is it conserving energy? This is clearly not simply qualitative. Again, it sounds like you’re assuming that your experiences should apply to all. I don’t think this is necessarily the case.
S-o-o-o-o-o-o-o-o, how does this all work out in a world full of Trumpkins? Any form of ‘so called’ science based policy making goes straight out the window, proverbially speaking.
I think we can let go of the, but modulz, argument David. I’ll take any science, some science over no science in any form of policy making, sans ‘so called’ gut feelings 247.
I found the article itself to be rather rambling, what is a math model and what is a statistics model. All models are wrong.
“I found the article itself to be rather rambling, what is a math model and what is a statistics model. All models are wrong.”
George Box, who coined the “All model are wrong, some are useful” nonsense, was a statistician, and may have first applied it to numerical errors (and then to everything else he thought about — likely imaging he was on to something profound — not really).
So of course Box could find some narrow case where Kirchoff’s Laws didn’t give the right answer, nit-picking down to the Nth-decimal point.
Paul,
I think Paul Box’s comment about models is pretty spot on. They’re mean to be representations of reality that allow us to understand how systems evolve and how they might respond to changes/perturbations. They’re not really right, but some of them are (very) useful.
You are right about discrete conservation Attp. It’s a quantitative verification test. Most modern methods do this. There are others such as the similarity analytic solution for a flat plate boundary layer. It’s becoming more common to do some simple verification testing. NASA has a web site with some simple test cases, often with test data and sone “reference code” solutions. These codes are the more well established nasa codes. These cases are intended to help verify that the code doesn’t have bugs or convergence issues. I’m still not exactly what “understanding the physics” means for you.
Validation is a much bigger challenge because it involves much more challenging cases. Sensitivity testing is not very common in fluid mechanics and is virtually nonexistent for time accurate eddy resolving simulations. Even grid convergence for Reynolds averaged simulations is an open question. We still don’t know if there is a unique infinitely fine grid limit. The current state of the art is only a small fraction of what is needed for credible uncertainty estimation.
The other problem is just selection bias. People like to get answers that agree with the data and there are lots of knobs to turn. People need to be encouraged to publish ensembles of solutions using a range of parameters and some of the better more recent work does that.
In commercial market research the goal is first and foremost to get the sampling and weighting correct. It drives up the cost of projects which displeases clients. But if we get it right there is much more latitude for, well, mistakes in analysis, which we politely call testing more than one hypothesis.
Because we already have the data and we trust it.
When I look at climate science I do not see a crisis–although there are issues remaining, I see serious efforts to continually improve data quality and that’s a sign of health in the field. I do see a problem with climate communications, but I won’t bore you all with a rehash. It’s been done to death and everyone is backed into their own corner.
dpy,
Again, you seem to be highlighting some things that could be better or that are indeed getting better. You’re also – as far as I can tell – focusing on issues in a field with which you have experience. Great, but this doesn’t mean that it applies everywhere, or that others aren’t aware of issues in their own field. I’m certainly not arguing that there aren’t issues in mathematical modelling and that there are no problems, but this doesn’t imply some kind of crisis. There are always going to be trade-offs and what might be regarded as crucial in one application may be regarded as not all that important in another.
A key problem I have with the idea of there being some kind of crisis is partly that it’s a simplistic representation of something that is clearly much more complex and partly because I suspect you could make such an argument at any time (i.e., research is never going to be perfect). I think that if people are going to argue that there’s a crisis, rather than the system simply evolving naturally, they need to show that there is something different about what is going on now compared to what has happened in the past.
All that one needs to do is find the exception that breaks Box’s quaint homily.
1979 is the earliest known reference to the quote

The model of Boolean algebraic logic used to design any conventional computational device is exact.
Paul,
Why would you want to break Box’s quote? It’s entirely reasonable if not absolutely true in all circumstances.
The problem is that if you actually do research, it is bound to be flawed.
All models are wrong.
It is facile to sit back and not do research, and instead point to (potential or actual) flaws in existing research and declare, without a systematic approach to quantification and qualification, that we’re in a “crisis.”
Which is the better alternative? Do research (some of which will be flawed) or not do research (and thus not do any flawed research)?
Some might argue that scientific research has, in balance been a detriment. Others would argue that scientific research has, in balance, been a significant asset.
Sometimes we see how some (many?) people move from one camp to the other.
For example, we might see a person saying that modern technology has reduced poverty and increased nutrition and longevity, etc. But then we might see that same person declare that scientific research is in “crisis” because over time flaws in research surface.
Yeah, that’s what most noteworthy, imo. What’s most noteworthy to me is when people seek to exploit scientific research in a contradictory manner, IOW in whichever way fits with their agenda (at the moment).
I find it noteworthy when things are simultaneously banal and interesting.
It seems to me that people are more upset that a model is not an exact prediction, but is instead a model. The largest cause of uncertainty in climate models is the response of humanity. Nevertheless, from the most simple to the most complex model–add CO2 to the atmosphere and it warms significantly.
I’ll finish with a discussion of maps–a model of the surface–from Lewis Carroll:
“That’s another thing we’ve learned from your Nation,” said Mein Herr, “map-making. But we’ve carried it much further than you. What do you consider the largest map that would be really useful?”
“About six inches to the mile.”
“Only six inches!” exclaimed Mein Herr. “We very soon got to six yards to the mile. Then we tried a hundred yards to the mile. And then came the grandest idea of all ! We actually made a map of the country, on the scale of a mile to the mile!”
“Have you used it much?” I enquired.
“It has never been spread out, yet,” said Mein Herr: “the farmers objected: they said it would cover the whole country, and shut out the sunlight ! So we now use the country itself, as its own map, and I assure you it does nearly as well.”
Mitch –
Thanks for that from Lewis Caroll. It’s perfect.
IMO, these quotes are excuses that reinforce a defeatist attitude in what is possible.
There is another quote by a statistician that originally was phrased as
“If you torture the data long enough, nature will confess”
and then changed to
“If you torture the data long enough, it will confess”
and finally
“If you torture the data long enough, it will confess to anything”
Notice that the first is a rallying cry to be persistent and not give up, but over time it was modified to warn against misleading research results.
Even more inspirational than Lewis Carroll is this:
“but it’s a full-scale model, sir !”
I’m using a mobile device so I apologize for any typos. I won’t quibble about the “c word” as I agree with you there is too much crisis mongering.
However there are important changes in the way some people are selling modeling and where it is applied that raise the stakes. Boundary layer theory is over 100 years old. By 1950 computers allowed modeling of 2D attached bl’s. It took 30 years to develop stable methods for 2D separated bl’s. These were used as guidance for design and are still workhorse models.
Now we have Reynolds averaged NS and LES and other eddy resolving simulations. These are much more poorly posed than integral bl models. And people are trying to do certification by analysis which is massively separated flows. The best nasa folks know they need to quantify uncertainty but very little has been done so far. You run the code until you get a credible result. There is usually inadequate person and computer time and funding to do the kind of sensitivity studies Saltelli talks about. LES or even DES simulations can take months even on a large cluster.
Generally (and the best turbulence modelers agree) there is overconfidence in these newer simulations and that grows as decision makers get further removed from the process. It’s very seductive because it’s easy to set up and run the code and generate colorful and complex and intriguing looking results. Careers are easy to build around this modus operandi.
Summarizing: in the past we used better posed but less general models. Now there is tremendous pressure to move all the way to the right on Saltelli’s figure 1 without understanding that uncertainty can grow dramatically when you do that. I actually think climate scientists like Palmer do a better job of explaining the uncertainties than leaders in other fields that rely on fluid modeling. But I think we need a lot more fundamental theoretical work and model running should focus on Saltellis points.
@ATTP,
Okay:
ecoquant,
I’m not quite sure what point you’re trying to make, but I wasn’t suggesting that it’s always fine to use null hypothesis testing, I was just suggesting that there’s nothing wrong with using it if you know how to do so.
dpy,
We seem to have these kind of discussions every year or so where you refer to turbulence and eddies and then make some kind of claim about climate modelling and it always seems to be a bit of a stretch. I think Saltelli has mostly illustrated that he doesn’t really understand how mathematical models are typically used, so I really don’t see why model running should focus on his points. I think most who run these models understand the limitations and strengths of these models. We can always do better, but that doesn’t mean that we don’t know anything or that there is some kind of crisis.
I agree that it can be difficult to properly interpret the results from very complex models, which is why I quite like keeping my models quite simple. On the other hand, if you want to understand the details of complex systems, sometimes you need to develop complex models. That it won’t be easy to develop, run, and interpret these models doesn’t suddenly imply some kind of major problem; it’s just how it is.
Paul Pukite — I assure you that Boolean algebraic logic only represents a portion of what digital circuits are supposed to do, much less what the circuits actually do.
@ATTP,
The point is that the correct answer is None of the above. This is not a trick question. I find when people do do hypothesis or significance testing, they often don’t know what the result means. They also don’t appreciate that, for example, p-values are random variables.
ecoquant,
Yes, I agree that many don’t know what the result means. I was simply agreeing with Victor that the problem isn’t null hypothesis testing, but that many don’t understand what the result means when they do such a test.
Later on Box played down the significance of the exactness of the models, instead focusing on the utility of approximations

So he says:
1. All models are approximations
2. All models are wrong
So asserting an approximation is wrong is merely stating a tautology. An exact approximation is akin to the pointlessness of Tomkinson’s ice-breaker or Carroll’s map.
It’s interesting to watch Box’s usage of this phrase over the years as you will find it arbitrarily inserted into many of his papers and books, functioning as a get-out-of-jail-free card.
> We seem to have these kind of discussions every year
I’d say every season or so. My favorite was when you wrote a post on exo-planets:
Perhaps I should follow-up on DY’s peddling the same way I do with RickA. Instead of mentioning a vegan factoid, I’d go for an engineering paradox, e.g.:
https://www.spiegel.de/international/business/737-max-boeing-s-crashes-expose-systemic-failings-a-1282869.html
We can agree to disagree ATTP. In looking at references I found this https://www.sciencedirect.com/science/article/pii/S1364815218302822?via%3Dihub
Which indicates that there is a problem to be addressed. This indicates that in many cases scientists don’t understand their models issues.
In the case of climate models one main problem is just the high level of numerical truncation error compared to the output quantities of interest. This implies that the model will only be skillful for quantities related to those used in tuning and that skill is the result of cancellation of errors. Of course these models are all we have.
Oberkampf, W. L., Trucano, T. G., & Hirsch, C. (2004). Verification, validation, and predictive capability in computational engineering and physics. Applied Mechanics Reviews, 57(5), 345. doi:10.1115/1.1767847
@ATTP,
I didn’t want my silence to be interpreted to mean I agree with this. I simply think there’s no point discussing it much more here. From my perspective significant testing or hypothesis testing have severe deficiencies, whether or not practitioners understand them. These include:
* never being able to accept the null,
* having the index of success, the p value accept or reject threshold depend upon intricacies of sampling details, such as sample size,
* reducing discoveries to dichotomies which would benefit from a more nuanced scoring, and
* not being readily able to combine evidence from successive or different experiments into a composite conclusion.
ecoquant,
I don’t think we really disagree. I’m just not a fan of blaming the tool when it’s mostly the worker. I also agree that that there are severe deficiencies. However, it still seems to me that the problem is primarily how it’s been used, rather than the method itself.
dpy,
Seriously, you’re going to highlight a paper by Saltelli? As far as I can tell, Saltelli doesn’t really understand this, so why would you think that I would suddenly regard a paper of his as illustrating that scientists don’t understand this. I always find these discussions with you to be really bizarre. In my experience, scientists are very well aware of the limitations and strengths of their models. This doesn’t mean that this is true for all, or that there aren’t some who don’t, but I’ve seen nothing to make me think that there is some major crisis, or that those who highlight this supposed crisis actually really know what they’re talking about. Have you considered that the reason you like this is because it gives you another opportunity to bash climate models?
Just a general comment, but one of the main problems that I think science has is over-hyping research results. A lot of research is important, but not all that interesting. There’s sometimes a tendency to make something sound much more interesting than it really is and I think this is something we should try to avoid. Saltelli’s work implies some kind of crisis in science. Is there actually a crisis, or is he simply an academic who has found a way to make his work appear much more significant than it actually is? Would it get much notice if he was simply highlighting that not all research papers do all the underlying analysis that maybe they should?
This part of this paper seems interesting.
I’ve been trying to work out what Saltelli means by sensitivity analysis and – based on the above – it seems that what he means by sensitivity analysis I would regard as “using the model”. When I’m running a model, I’m often interested in how the output depends on the input. I wouldn’t regard this as a sensitivity analysis, but as one of the key research goals.
” In my experience, scientists are very well aware of the limitations and strengths of their models. ”
Indeed, it is difficult to improve your models if you don’t have an unbiased view of the current model’s limitations and strengths. It is a bit of a career-limiting issue if you don’t! However, hubris on blogs is very common, no shortage of armchair quarterbacks ready to tell scientists they are doing it all wrong (but not making any attempt to do better themselves).
“Just a general comment, but one of the main problems that I think science has is over-hyping research results. ”
Absolutely. Machine learning is doing that for at least for the third time with “deep learning” (which is very interesting, but AFAICS only for some kinds of problem; there are others where they fail miserably).
I disagree, strongly. Null hypothesis testing is wrong. Bayes Factor method is right.
I disagree. Bayesians can perform null hypothesis testing as well. NHSTs have their uses, especially in situations like quality control where the idea of long run frequencies is what you actually mean by a probability. Bayes factors are not without their problems as well, particularly where you do have some knowledge of the nuisance parameters that you marginalise over, in which case the “Occam factor” that penalises more complex models is too high (sometimes substantially) if you use an uninformative prior. If you don’t use an uninformative prior, you then get into the problem of whether your “opponents” (i.e. review 3 ;o) will accept it.
Personally, I think statisticians should have a good understanding of both frameworks and use the tool that provides the most direct answer to the question as posed (also considering the questioner’s needs and requirements).
Agreed that uninformative priors have problems, not the least being they almost always misconstrue what’s known. I find people use them out of laziness.
But weakly informative priors can. Have all the benefits of informative ones from a rhetorical perspective and few of their drawbacks. Also standard Bayesian practice calls for re- running and reporting results from a handful of alternative weakly informative priors. Anyway, with enough data and some probability mass on every part of the allowable parameter space, the prior can”t really exclude any possibility.
Note also there’s work in “objective Bayes” championed originally by Berger.
There are other problems for Bayesian practitioners. While computational obstacles used to be major, with well constructed hierarchical models and suitable hardware and software, they aren’t any longer. However, Likelihood functions derived from models can be complicated and error prone, giving rise to model specification error. This led to the development of ABC methods (Approximate Bayesian Computation). These serve a role akin to secant methods in non-linear optimization of continuous functions where the need for calculating high numerical or closed form derivatives of Newton methods is avoided. However, the theory of ABC is not as well developed as secant.
Wasn’t much pushback to this assertion:
It was seconded by this
David B. Benson says:
That’s just the tip of the iceberg as far as “correctness” of logic design models. Can argue this, but it might be impossible in the future to synthesize a sophisticated chip without starting from a comprehensive model. The next stage of improvement is whether formal verification will supplant exhaustive simulation of the models.
https://www.electronicdesign.com/industrial-automation/11-myths-about-formal-verification
This is interesting:
Many of the complex systems on a chip that go into a mobile device or other consumer electronics start and end as honest-to-goodness models, and you have Box saying they are all wrong, but some are useful? In certain disciplines, Box’s quote is a homily for a bygone era.
The reason I gave the Saltelli reference is because it does a good job of defining sensitivity analysis and how to do a good one using Design of experiments methods. Doing it well is a lot of effort and the effort increases as model complexity increases. That’s why it’s rarely done for complex models except in conjunction with numerical optimization. Their literature survey looked to me to be well designed too and the conclusions are what I’ve found personally. However I’m not a statistician so I’m not equipped to draw strong conclusions.
There is another mathematical paradigm here that I think has influenced the verification and validation paradigm. In well posed models, it is indeed possible to verify things like grid convergence which are pretty strong indicators of mathematical correctness. Validation usually requires data to compare to. This paradigm has historically been pretty useful. Shadowing methods could be a key idea for extending it to dynamical systems.
dpy,
To me, it illustrated the issue I have with this. What Saltelli calls “Sensitivity Analysis” is what I might call “doing my research”. I can understand that if you’re trying to model how some system might respond to a specific input, you might want to also check how sensitive it is to variations in that input. However, if I’m trying to understand how a specific type of planetary system evolves, I might run a suite of N-body simulations with a range of different initial planetary systems. I wouldn’t call that a sensitivity analysis, it would simply be a set of simulation aimed at answering a scientific question. Someone else could use exactly the same model to answer a different scientific question, so how my model output depended on the variations in my input would be completely irrelevant for their research.
So, again, it seems that there may well be cases where what Saltelli calls a Sensitivity Analysis should be done. I simply don’t see that this applies across all of mathematical modelling.
dikanmarsupial & eqoquant — The Bayes Factor method does not use priors. It simply compares two hypotheses as to which better describes the data, and how much better. See Akaike Information Criterion.
David – yes it does. If you have nuisance parameters then they get marginalised with a prior. I think you are confusing a Bayes factor with a likelihood ratio. AIC is not a Bayes factor – it is a likelihood with a complexity penalty, which is a different thing entirely AFAICS, but I’d be happy to see an explanation of their relationship (personally I prefer cross-validation for model comparison).
> The reason I gave the Saltelli reference is because it does a good job of defining sensitivity analysis and how to do a good one using Design of experiments methods.
I thought it was because it was Saltelli all the way down. It’s the fifth reference from the paper on which AT comments. Incidentally, that paper has 16 citations. Four are by Saltelli. Of the 12 others, there are the usual three Ravetz cites, one classic piece from 1972, and four random books. That leaves four articles: Eker & al 2018, Brauneis & Goodman 2018, Popp & Hirshman 2018, Rayner 2012. Which means Saltelli padded his reference list in a way that obscures the fact that among the most relevant citations he self-cites himself half of the time.
Take a look at how they established their result. You might be surprised. It’s far from being contrarian-proof. Hint: they cannot have shown falsity with what they did.
From what I understand, cross-validation is one of the the few approaches that are of any value for climate science. DPY’s suggestion that Design of Experiments will work at all for verifying climate models is misguided. There really is no experimental control possible for parameters such as volumes of water the size of oceans and gravitational forcing on that same scale. Back to Tomkinson’s ice-breaker times 1000000.
You have to take the data as given and use some creative analysis, which is what cross-validation is about.
@-ATTP
“Saltelli’s work implies some kind of crisis in science. Is there actually a crisis, or is he simply an academic who has found a way to make his work appear much more significant than it actually is?”
I think it is worse then that.
It seems clear that Saltelli has little experience with how climate models are made and used, and not much more with statistics. His paper is never going to be cited by those involved in climate modelling and has absolutely no traction within the field. It lacks domain relevance.
Which begs the question, who, and what, is it for ?
Is the intended audience for the Saltelli paper others within his academic field, where this may pass as original and important research that will score him brownie points and further funding ?
Or is it intended for a wider lay audience who are sufficiently unfamiliar with the field of climate modelling to be unaware of the deficiencies of the paper, but welcome (like dyp) any punitively authoritative ‘voice’ that finds a spurious ‘crisis’ in AGW.
@David B Benson, @dikranmarsupial,
I agree with @dikranmarsupial. BFs might not involve priors if they cancel top and bottom, but that isn’t always the case. See Kass, 1993, “Bayes factors in practice”.
Moreover, at least from my perspective there are issues with BF hypothesis testing. I’d rather work directly from the posterior density, as illustrated by Krusche, where there is no hypothesis test:
And I don’t see what AIC has to do with anything. It’s posed as a correction for overfitting. There are Bayesian Information Criteria, and there is a correction to AIC called AICc, and there’s a Widely Applicable Information Criterion, and these have their uses. See, for instance, Burnham and Anderson, Model Selection and Multimodel Inference (2002), or Konishi and Kitagawa, Information Criteria and Statistical Modeling (2008). But these are only weakly tied to Bayesian inference, but Burnham and Anderson make some connecting remarks in their Chapter 6. Konishi and Kitagawa discuss BF a bit in their Section 9.1:
Following up on my remark regarding ABC above, a general introduction is available in:
Sisson, Fan, and Beaumont, “Overview of Approximate Bayesian Computation“, (2018)
An application to climate modeling is available in
Holden, Edwards, Hensman, Wilkinson, “ABC for climate: Dealing with expensive simulators“, (2015)
Have you considered writing a post on this, ecoquant?
> Or is it intended for a wider lay audience who are sufficiently unfamiliar with the field of climate modelling to be unaware of the deficiencies of the paper, but welcome (like dyp) any punitively authoritative ‘voice’ that finds a spurious ‘crisis’ in AGW.
Check this page:
https://en.wikipedia.org/w/index.php?title=Talk:Sensitivity_analysis&action=history
Look for “Saltean” and “WillBecker.”
Something tells me we got a budding fishing club here.
@Wlllard,
Actually, yes, it’s having arisen here makes me think I should. I first need to get one out summarizing and reviewing Zhang, Song, Band, and Sun “No proportional increase of terrestrial gross carbon sequestration from the greening Earth“, JGR Biogeosciences, 2019.
I think ATTP Saltelli is describing a more formal process in which you sample the parameter space in some initially randomly distributed way. There’s lots of good frameworks out there for this. Many are part of optimization packages. For optimization you fit a response surface to the outputs and optimize that. You can iteratively improve the quality of that surface, look at main effects, and lots of other interesting diagnostics. There is good statistics behind it too. At least that’s what my statistician collaborators tell me.
As you say good research often does this in a more ad hoc way. One point the Saltelli paper makes is that a lot of the papers they looked at did simple perturbation of one parameter at a time. This is perfect for a linear model but is far from optimal in the nonlinear case.
Having a reliable model is very helpful in this context. After 20 years of more ad hoc testing looking for grid convergence, conservation and other verification tests we had some surprises with optimization which tends to exploit model weaknesses. It takes work but can lead to important insights.
dpy,
I’m not suggesting that it be done in some ad hoc way, I’m suggesting that what he’s describing as a sensitivity analysis isn’t what modellers would necessarily call a sensitivity analysis. So, maybe the reason he think it’s isn’t being done is because he’s searching for a term that modellers don’t use to describe this process.
https://en.m.wikipedia.org/wiki/Bayes_factor
“In statistics, the use of Bayes factors is a Bayesian alternative to classical hypothesis testing.”
“In my view, it’s important to understand when one can use a statistical method/mathematical model, be clear about the assumptions used, and be clear about the limitations and strengths of the model/method.”
This is exactly what needs to be done in general and, at least in the scientific journals I am submitting to, is standard procedure to ask for during the review process. This is what I tell my students during my lectures and what my colleagues do, too.
An observation I made is, that the further away some people’s research is from basic science and the more the area of research differs from the methods used (stat. models in medicine, economics, biology, social sciences etc.), the less frequently those points are addressed properly. Again, only an observation initiated by suspicion and hardened over the years after talking to many scientists from other areas. I don’t have robust data to proof that, of course ;-).
Could be that including verification and validation might have cast a broader net. Sensitivity analysis has a very specific meaning in optimization that is not what statisticians mean. In optimization it means just partial derivatives with respect to the parameters. So they might have even selected some of these papers that don’t belong in the sample. And your point is also true.
However his conclusion still seems to me to be correct. Even papers claiming do do sa often do a poor job and that’s my experience too. Recently fluid dynamics has been doing quite a few model intercomparison workshops and those have more sa even though it’s mostly ad hoc. It’s just very expensive and time consuming to do a proper analysis so most people don’t. Especially with very costly models like climate models or LES models, computer resources really limit what can be done.
@David B Benson,
Yes, that characterization at Wikipedia is now pretty tired, if not misleading. I’ve opened a discussion on its associated “Talk” page to fix it. The Wikipedia page on Bayesian model selection simply redirects to the Bayes factors page, and that’s really bad.
Indeed, their current treatment of a lot of Bayesian methodology is out-of-date and slipshod, e.g., the description and presentation of Bayesian model averaging both in itself and as a subsection of ensemble learning.
This is too bad, because some of their purely technical pages are pretty good. Unfortunately, because this is a volunteer effort, it’ll need to be assigned a low priority, even if I am a member of the Wikipedia Statistics Group (or whatever it’s called).
This is kind of an antidote to the negativity of DPY. A while ago Terry Tao proposed that at some point we would be able to master the smallest details in fluid dynamics and perhaps apply this knowledge
https://www.quantamagazine.org/terence-tao-proposes-fluid-new-path-in-navier-stokes-problem-20140224/
He’s still working this problem with his latest from a couple of weeks ago “Quantitative bounds for critically bounded solutions to the Navier-Stokes equations” at ARXIV and in his What’s New blog.
> Recent fluid dynamics
As promised:
Paul,
See …
Hydraulic analogy
https://en.wikipedia.org/wiki/Hydraulic_analogy
Although some people can screw up the analogy, see Monkers, badly (assume everything is linear between absolute zero and GMST).
“I think ATTP Saltelli is describing a more formal process in which you sample the parameter space in some initially randomly distributed way.”
DPY have you heard of “perturbed physics experiments”?
David B Benson wrote “https://en.m.wikipedia.org/wiki/Bayes_factor
“In statistics, the use of Bayes factors is a Bayesian alternative to classical hypothesis testing.””
Typical blog exchange. Someone makes a statement that is incorrect. They are corrected by two people who actually do know something about the subject. Instead of admitting their error, just post a link to Wikipedia with a cherry picked selective quote that doesn’t refute what was actually said.
It is a pity hubris and evasion can’t be used as a fuel source or the climate change problem would have been solved long ago.
DPY wrote ” Sensitivity analysis has a very specific meaning in optimization that is not what statisticians mean. In optimization it means just partial derivatives with respect to the parameters.”
Fisher information matrix? Oddly enough statisticians use Jacobian and Hessian matrices for a wide range of things.
dikanmarsupial — This is a low bandwidth media. It wasn’t at all clear, and still isn’t, that you know much about the subject.
It is important to communicate clearly just how poor traditional null hypothesis testing is. Billions of dollars are unnecessarily spent because the US government EPA and NRC don’t use Bayesian statistics.
So don’t try to show off, please.
“Billions of dollars are unnecessarily spent because the US government EPA and NRC don’t use Bayesian statistics.”
Circa Trumpkin, they don’t even know how to use a four function calculator correctly!
Maybe we can halt the discussion about Bayes factors, it doesn’t seem to be going anywhere constructive.
ATTP, sorry, missed that. Just want to make one last point. There is nothing that wrong with null hypothesis testing, just their mindless application. The problem is that they are conceptually subtle, but simple to perform, which makes the mindless/cookbook/null ritual approach accessible to those who don’t know what they are doing. The use of Bayes factors is not likely to be a huge improvement if they are similarly performed without understanding (for instance, ignoring the fact that priors are often involved in the marginalisation over parameters that is typically required).
I suspect the same is true for the “sensitivity analysis”/“doing my research” issue. It isn’t a matter of following some “roadmap for research” (thou shalt do this, thou shalt do that, that shall not do something else); it is a matter of understanding what you are doing and applying whatever tools are suitable for the problem you are trying to solve or question you are trying to answer.
> It is important to communicate clearly just how poor traditional null hypothesis testing is.
Then writing a post on this may be more profitable than yet another showdown.
I discussed one of the issues here: https://skepticalscience.com/statisticalsignificance.html. The paper on “mindless statistics” I posted earlier is also very good.
Traditional null hypothesis testing is poor in the sense that a screwdriver is a poor too for driving in a nail (or perhaps an allen key would be a better analogy ;o).
Thanks. I believe DavidB is this DavidB. He’s also the one who wrote:
http://rabett.blogspot.com/2013/02/on-priors-bayesians-and-frequentists.html?showComment=1360377072391#c3029782101587496133
So generalities may not be enough for what DavidB has in mind.
Efron’s text is quite good (I might be biased):
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.306.4592&rep=rep1&type=pdf
Michael Jordan’s video lectures are still around:
http://videolectures.net/mlss09uk_jordan_bfway/
@Willard, and all,
And since you are visiting the land of Stanford-style statistics, don’t miss the article I posted earlier by Efron and Morris on Stein’s paradox. For more see another tutorial by Efron and Morris.
James-Stein estimation is not Bayesian. But there are deep connections, and the notion of shrinkage which it introduced is important for Bayesian and other hierarchical modeling. Bayesian inference preceded the discovery of Stein’s Lemma historically, but Bayesian inference can be seen as a conceptual response to what Stein’s implies.
The reason I belabor this is traditional significance testing and hull-hypothesis testing can’t make heads or tails of Stein’s lemma …
Even Maximum Likelihood Estimation can’t. So, it’s entirely proper to think there’s something conceptually broken about these. Efron and Morris went in the direction of empirical Bayes estimation, where, basically, priors are estimated from data. In some respects, from a Bayesian perspective, this is cheating, and it denies the practitioner the ability to imbue a model with domain knowledge.
I’m a Bayesian, but I look at Bayesian inference and computation as an optimization problem, so I’ll happily apply things like Spall’s methods to it (including evolutionary computation!).
FWIW, I am this Dikran Marsupial, but in my spare time I am also this Gavin Cawley (not showing off, I am not utterly ignorant of statistics, but there are plenty with better statistical understanding than me).
I’m also a Bayesian (at least by inclination if not always in practice), but I’m also an engineer, so I’m happy to see the value in tools that are of some utility for some job, even if they are not perfect.
I’m also a fan of Efron and the bootstrap.
“Its reliance on prior beliefs has been challenged by frequentism, which focuses instead on the behavior of specific estimates and tests under repeated use. “
Ironically one of the key problems with frequentists NHSTs is that (at least in the “Null ritual” settiing), they *don’t* use prior beliefs, when of course they should still enter into the analysis (Fisher wrote that the “significance level” should depend on the nature of the problem – i.e. your prior belief about the H0).
Most problems with NHSTs stem from not understanding that frequentists fundamentally cannot assign a probability to the truth of a hypothesis (which includes “is the true value in the confidence interval I have just calculated). Once you get your head around that, and realise the NHST is not giving you a direct answer to the question you really want to ask, most of the problems go away.
BTW Grant Foster (a.k.a. Tamino) has a really good book on basic stats, with an emphasis on understanding what you are doing, well worth a read for anybody just getting started with stats.
> it’s entirely proper to think there’s something conceptually broken about these
What’s not proper is to simply assert it. I personally don’t care one way or the other, except perhaps for my belief in Jordan’s demonstration that the frameworks are more or less equivalent.
Speaking of which, you might like:
https://www.intechopen.com/books/advances-in-statistical-methodologies-and-their-application-to-real-problems/why-the-decision-theoretic-perspective-misrepresents-frequentist-inference-revisiting-stein-s-parado
@Willard,
I did. That what Stein’s Lemma shows, at least for . But even for
. But even for  , because the
, because the  value obtained depends upon the "stopping and testing intentions" of the experimenter, to use a phrasing advocated and popularized by Kruschke and Liddell, it is highly volatile. Would another experimenter have the same?
value obtained depends upon the "stopping and testing intentions" of the experimenter, to use a phrasing advocated and popularized by Kruschke and Liddell, it is highly volatile. Would another experimenter have the same?
If the original experimenter intended to collect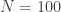 observations, but, because of difficulties, only collected
observations, but, because of difficulties, only collected  , would another experimenter know they intended
, would another experimenter know they intended 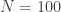 ? Realize that the
? Realize that the  value is affected by these considerations, and won’t, in general, properly be either that corresponding to
value is affected by these considerations, and won’t, in general, properly be either that corresponding to 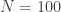 or
or  but from a sampling distribution considering
but from a sampling distribution considering  as a random variable, and that’s not either of those. Indeed, what’s needed to calculate an accurate
as a random variable, and that’s not either of those. Indeed, what’s needed to calculate an accurate  value is doing it for each possible
value is doing it for each possible  and then doing a weighted average of
and then doing a weighted average of  values using the probability of each possible
values using the probability of each possible  . How does the experimenter actually do that? Would another experimenter have the same probability masses on
. How does the experimenter actually do that? Would another experimenter have the same probability masses on  values?
values?
Further, the criterion for comparison depends upon assessing the effect size for the experiment.
This is a never-ending pit.
I’ll have to watch Jordan’s talk, but the two frameworks are not equivalent as far as I can see, because one framework can attach a non-trivial numeric probability to the truth of a particular hypothesis and the other can’t. Thus a frequentist test can never tell you the probability that the null hypothesis is false, which arguably is a useful piece of information in most applications of hypothesis testing. They can be applied to the same problems, but then both hammers and screwdrivers can be used to drive in a screw ;o)
> This is a never-ending pit.
Audits, in general, never end.
I did not mean to imply you did not show anything for your claims. It was meant as a general comment, i.e. as long as one can argue for one’s case, all should be well. Only stating one’s belief is also fine, as long as it stays there.
I think it may be John Tukey who was first on record to pose the following: What is the collective noun for a group of statisticians? Answer: A quarrel.
If this thread is to be taken as any evidence, the epithet remains as appropriate as ever. So, in answer to the question, ‘Is statistics currently in crisis?’, my answer would be, ‘When has it ever not been?’
John,
In a sense that is somewhat related to what I’m suggesting. Most research areas are constantly evolving. Research is about continually tackling new problems, which typically require new methods and new approaches and there will always be stages when people are learning about which methods are most appropriate and how to use them. The real issue is whether or not our current approach to research is leading to us developing a better understanding the world around us. I think the answer is broadly “yes”. This does not mean, though, that we couldn’t do things better and that we shouldn’t be aware or possible problems. For example, I think scientists do over-hype their research, I think the system is geared towards those who appear to do impactful research, rather than those who do careful research, and I think we have to be much more aware of how we encourage, and promote, diversity within research areas. I don’t think, though, that there is some kind of crisis, at least not of the sort described by Andrea Saltelli.
I can’t watch back MichaelJ’s lecture right now. I don’t have access to Flash anymore. It’s a good thing, as we’re replacing our roof today and the electrician is coming up soon. His slides [MichaelJ’s, not my electrician’s] are less informative as I’d like, but they’re still good. If memory serves well, I discovered this talk via Less Wrong:
https://www.lesswrong.com/posts/wnpvtzrdpqsFmKxKu/michael-jordan-dissolves-bayesian-vs-frequentist-inference
I’ve seen some unified models, e.g. Berger, Boukai & Wang 1997. Arguing for one or the other would undermine the overarching point I could put forward – if frequentist approaches are misapplied, then we should expect that Bayesianism will be too, e.g.:
It’s always possible to go wrong, except perhaps when one becomes a subjective Bayesian. (In case that’s not clear, it’s a joke.) But even then, optimality comes at a cost.
John Ridgway I think Michael Jordan and I are in broad agreement that you should be both a frequentist and a Bayesian; both have their advantages and disadvantages.
Perhaps that just means that I am disagreeing with both sides ;o)
How appropriate: Professor Hannah Fry of the University College of London writes on “What Statistics can and can’t tell us about ourselves“.
She mentions Loop champion Professor David Spiegelhalter. He previously did Understanding Uncertainty.
Perhaps the crisis is in finding new models of physical behavior that are clearly distinct from a random background or nuisance signals. It’s not as if the end of applied mathematics is upon us, just that it’s getting harder to find novel applications for the math available, and so people are stretching to find correlations that might not exist. I never look at a p-value, because my guideline is that if whatever you find requires a p-value to convince someone of its validity, then it might not be worth to pursue. There must be some other way to demonstrate its validity.
Dikran,
“I think Michael Jordan and I are in broad agreement that you should be both a frequentist and a Bayesian; both have their advantages and disadvantages.”
And I think that is a very healthy and pragmatic stance to take. Nevertheless, the history of the frequentist versus Bayesian debate has often been fractious to say the least – and for many it remains a bone of contention. Does this constitute a crisis? I’m not sure. I suppose it is a matter of personal judgment as to what point the level of professional disagreement shifts from being healthy to problematic. If I were to judge that the ideological debates within which statistical theory often become mired have a tendency to cross the line, I probably wouldn’t be on my own. I guess the aim should be to remain pragmatic.
Dikran Marsupial and John Ridgway, as the statistical moderates in this steam, I would be interested in your take on my earlier comment.
ATTP: “It’s also not a problem that exists in all research areas; it’s predominantly in areas that have relied on null-hypothesis testing. There are – as far as I’m aware – many research areas where this really hasn’t been a major problem.”
VV: “This does not say, but suggests that Null-hypothesis testing is the problem. My impression is that the problem is for fields without much theory (a-priory humans respond in almost any way) and small sample sizes (because collecting data is expensive).
I would be surprised if the use of Bayesian statistics in psychology would have averted their replication crisis.“
Victor,
It does seem that a fairly benign comment from you and a fairly benign response from me, has lead to a rather lengthy debate about frequentist versus Bayesian statistics 🙂
My apologies, I should have known to be careful with the B word.
ATTP,
The readiness with which a frequentist versus Bayesian debate broke out should tell you something regarding the fundamental divisions that still exist within the statistics community. I think that they go beyond the run-of-the-mill controversies that are bound to exist within a developing area of research. Maybe ‘crisis’ is an overstatement, but it would also be wrong to underplay the extent to which contention is haunting the house. And we haven’t even started to discuss the non-additive alternatives to probability theory…
I keep telling myself that I should do some reading on Baysian statistics, but for years (well decades) I have been asking myself why so many statistical applications in research seem to go back to a starting position of “we know nothing about this system”, ad then just feed data into a stats package….
@Bob Loblaw,
Highly recommend Kruschke’s Doing Bayesian Data Analysis: It’s written for undergraduates and is intended to completely replace the early sequence in Statistics.
John Ridgeway wrote “Nevertheless, the history of the frequentist versus Bayesian debate has often been fractious to say the least – and for many it remains a bone of contention. Does this constitute a crisis?”
No, it isn’t a crisis because both frameworks are useful if you are aware of the pitfalls and problems and there is nothing to stop you from using both. The real problem is the users of NHSTs (and to a lesser extent confidence intervals) using them badly without understanding what they actually mean, and thus not knowing they are using them badly.
VV I would agree that the replication crisis in psychology isn’t just a problem with NHSTs, it is a difficult subject for a variety of reasons. NHSTs have problems with “big data” as well as that often means you have a highly significant outcome where the effect size is too small to be of any practical meaning (and often, for instance testing for normality, you know the null hypothesis is certainly false a-priori). However most of these things are pretty well known, so I am wary of claims of “crisis” in the same way that “it’s a wicked problem” immediately raises my suspicion ;o)
Astronomy has largely switched to Bayesian statistics. It took some time, but it wasn’t really fractious. It just took a little while for the various tools to become available.
Yes, tools like BUGS and STAN etc. make things a lot easier – the practical problem with Bayesian stats is the need to integrate things (and often you have to invent a new recipe for each problem, rather than just reach for the cookbook – but that is probably a good thing ;o). If only I had the energy to learn to use them ;o)
@ecoquant
Agree to the book recommendation. Bought it, too, for my research group. Very accessible.
@dikranmarsupial,
There’s also the highly useful MCMCpack of R as well as EasyABC and a number of packages which MCMC built in. The other is coda and it’s diagnostic tools … Very much worth learning those.
The primary skill is learning how to set up Bayesian hierarchical models and what makes certain ones converge slowly or not at all.
As noted Doing Bayesian Data Analysis</em is a real gem or working through the examples of MCMCpack and their associated original papers.
Dikran,
Back in the 1930s, in University College London, Bayesians and frequentists (Neymanites and Fisherites, to be precise) would have nothing to do with each other. So the Bayesians would use the common room between 3:30pm and 4:15pm, sipping India tea, and the frequentists would use it thereafter, to sip their China tea. Nowadays, statisticians are less clannish and more inclined to drink a mixed blend – the worst of their ‘crisis’, it seems, is behind them. And, as you say, it isn’t just the statisticians’ penchant for an ideological bun fight that is the problem here – it’s the failure of others (who should know better) to properly understand the statistical concepts they employ. In a study into levels of competence within practitioners of psychology, published in Psychonomic Bulletin & Review (“Robust misinterpretation of confidence intervals”), Rink Hoekstra of the University of Groningen in the Netherlands, reported that:
“Both researchers and students in psychology have no reliable knowledge about the correct interpretation of confidence intervals …researchers hardly outperformed the students, even though the students had not received any education on statistical inference whatsoever.”
That being the case, it is psychology rather than statistics that appears to have the real crisis.
John,
I don’t want to back psychology specifically, but I do think the issue is more prevalent in some fields than in others. Statistical analyses are very common in astrophysics and – as far as I can tell – a good number of my colleagues are very well aware of the correct application of such methods and are very careful about how they apply them. This doesn’t mean that there are no problems in astrophysics, but I don’t see any evidence for some kind of crisis in terms of how statistics is applied.
John –
> That being the case, it is psychology rather than statistics that appears to have the real crisis.
I think we’re all in a crisis due to so much alarmism.
ATTP,
“This doesn’t mean that there are no problems in astrophysics, but I don’t see any evidence for some kind of crisis in terms of how statistics is applied.”
That’s certainly good to hear. Crisis is indeed an over-used word, and it may be hyperbole to suggest that either statistics or mathematical modelling are in crisis. Besides, any such claims need to be evaluated within the broader context of the scientific endeavours into which they are co-opted. The contributors to this forum may have differing views as to whether there is anything even approaching a crisis within science as a whole, but I don’t think it can be denied that there is a growing disrespect within some quarters of society for expert opinion and if such a trend were to go unchecked then ‘crisis’ may not be too strong a word for it. One can argue the toss over the causes and extent of such disenchantment but one of the accusations that has been levelled is that there is now just too much ‘science’ and too little quality control. If there is any basis to this allegation then one would expect it to be focussed upon those practices for which quality control and prudence have the greatest importance, and I can’t think of any two circumstances for which this is truer than when undertaking statistical analysis and mathematical modelling. Both may be more sinned against than sinning, but that could be a small comfort.
John,
It’s my understanding that there may be sectors of society that distrust experts, but that – in general – there is quite a lot of trust in experts. There is even a paper that has looked at this, which says:
Of course, it’s only one paper. My own view (based on nothing other than my limited experiences) is that it’s not so much a lack of trust in experts, but a lack of trust in those who say things that may be regarded as inconvenient. It’s something worth considering, but I do think that experts should be (mostly) free to say things that society finds challenging.
@ATTP, @John Ridgway,
It’s interesting looking at quantitative techniques in multiple fields how most remain pretty insular. In fact, arguably the best apology I have heard from fields for continuing to use NHST is that it’s what referees expect. (By the way, Doing Bayesian Data Analysis is as much an introduction to proper NHST as it is to Bayesian methods. That’s needed in order to both clean up the practice of NHST and to make it clear why Bayesian methods are better.) Often, I think, technical fields remain this way, until some upstart from a related field comes in and publishes a new way of thinking.
For example, and mentioning another quantitative method, it took a long time for kriging to be appreciated outside of mining, and yet it is a major statistical technique, now having robust statistical foundations, and even Bayesian formulations. It matters: Much of the Berkeley Earth Surface Temperature project wins because of kriging and the efforts of Zeke Hausfather. Moreover, kriging brings a new way of thinking about point density estimation to the problem, that of Gaussian fields. Ultimately that’s about mathematical manifolds, but it’s a start, and the conceptual shift is important.
I’ve found it amusing over the years that some papers on use of Bayesian methods in geophysics end up getting published in purely statistical journals, as if the geophysical journals really weren’t interested. But the geophysicists really ought to pay attention to the amazing things quantitative ecologists do these days.
“but I don’t think it can be denied that there is a growing disrespect within some quarters of society for expert opinion”
There has never been a shortage of hubris – I suspect that blogs etc. mean we see more of it unfiltered than we used to.
ATTP,
Yes, the question of trust in experts is far from straightforward. Also, we are not just talking about scientific experts as far as the public is concerned, but experts of all stripes. Basically, anyone who is in the prediction business can expect their acumen to be questioned once they start getting it wrong too often, or at least once they are perceived to have gotten it wrong. Furthermore, the reputation of a group will suffer if it updates its advice too often in a self-contradictory manner. I’m not saying this is rife, but it does happen, and it doesn’t go unnoticed. Even so, given the track record of some experts, the public trust can seem remarkably resilient, backing up your assertion of a general (perhaps predilective) trust in experts.
@dikranmarsupial,
Not really a new thing …
— Bernard Shaw
John –
> but I don’t think it can be denied that there is a growing disrespect within some quarters of society for expert opinion.
Usually, imo (and I have seen some supporting evidence) the disrespect for expert opinion is rather selective; it isn’t a generalized disrespect, but one which takes shape through an ideological or cultural filter.
I’ve also even evidence of aire generalized disrespect, but that so takes shape through a political filter. For example, there has been a rather moderate signal of increased lack of “trust in science” in the US, but that increase has been in a very specific segment of the public (a minority in the right, not the left or moderates) and the causality (as you allude to) is rather complicated. Some evidence suggests that it is associated with an increased political interest of the religious right – which has an effect on views such as stem cell research, evolution, etc.
I think your attention of causality to issues of “quality control” deserve due skepticism. People tend to attribute low quality to science that has implications they don’t like. And they use quality problems to rationalize their ideological and political predisposition.
Joshua,
…”the disrespect for expert opinion is rather selective.”
I think that is a very valid point but I would venture to generalize it by saying that everyone’s regard for expertise will be filtered by their confirmation bias, and so both trust and mistrust becomes rather selective. A problem with expertise is that it often begs the appreciation of those who lack it.
John –
> and so both trust and mistrust becomes rather selective.
Sure. I think we can expect it to run both ways. And I’d guess that we might expect that a signal of opposite tends of prevalence (trust vs. distrust), specific to issue and ideological groups, to be hidden in aggregated data.
There is some evidence that in the US we are becoming more partisan and polarized, generally. If so, we might expect the political leveraging of trust in experts to grow.
“Science never solves a problem without creating ten more.”
that’s a good thing, isn’t it? ;o)
Kalman filtering and kriging are similar approaches, AAIAC. They just put a special name on it because the application there is to a 2D or 3D spatial process.
@WHUT,
Paul,
I think “Kalman filtering” (which really ought to be called Rauch-Tung-Striebel smoothing since Kalman didn’t really do the smoothing part.
As far as comparisons with kriging goes, RTS smoothing admits a lot more structure than kriging does. That is, for instance, in banking and economic applications, you can build coupling structure into the transition matrices, and limitations on observables into the state-to-response matrix.
As far as I know, this isn’t customarily done in kriging, where the matrices are constructed from datasets, and, in the case of extreme idiosyncraticity, from the local neighborhood.
Also, on the flip side, there’s nothing necessarily optimal about the RTS smoother, whereas kriging is BLUE almost by definition. Depending upon how the model is specified, the RTS can have bias as well as specification error.
“For example, there has been a rather moderate signal of increased lack of “trust in science” in the US, but that increase has been in a very specific segment of the public (a minority in the right, not the left or moderates) and the causality (as you allude to) is rather complicated. ”
The left has little trust in scientists who work in the private sector, the military, nuclear physics, or agriculture-related genetics. The right trusts nobody in environmental sciences.
Both (with some exceptions- genetics in particular) can provide excellent examples for their distrust.
Jeff –
I realize that the point of all your comments here is partisan politics – but you really should look at the data before you make such comments. You should attempt to exercise some control over the influence of your own political biases.
eco.
kriging changed my whole conception of the problem. that day when I “got it” ( old dogs)
was a game changer for me.. haha kinda like the day years ago when a guy explained kalmen
filtering to me.
jeffnsails850 says:
“The left has little trust in scientists who work in the private sector”
??? Bell Labs, IBM Watson
He must be very young.
Krigging is also the basis for Gaussian Processes (essentially a non-linear Bayesian generalisation of generalised linear models), which have been a topic of intererest in machine learning for a decade or so.
“??? Bell Labs, IBM Watson. He must be very young.”
???Exxon, BP, Westinghouse Nuclear, EIA, IEA. You should read the posts by a guy named Paul Pukite.
Joshua, I looked at the data on the GMO controversy, the claims of the peak oilers, and the stuff from the anti-nuclear movement. You should try it, you’ll find the anti-science comes from the political left and rejecting it is (was?) actually bi-partisan in the US, which is why I drove people to the polls to vote for Bill Clinton in ’92 and ’96 when the party was thoughtful. Did you watch the CNN townhall on climate last night? I did.
I DVR’ed the whole CNN climate townhall thing and every single candidate seem to know about 10X what Trump does about climate change.
But only one Democrat candidate addressed the ‘question that can’t be asked’, global population growth. Bernie Sanders did. As expected the media is tearing into him to pieces for this thoughtful observation: “Empowering women and educating everyone on the need to curb population.”
First rule of problem solving. Stop making things worse – reverse the growth of global population and technology will handle the rest.
Sanders/Warren 2020
Jeff –
> Joshua, I looked at the data on the GMO controversy, the claims of the peak oilers, and the stuff from the anti-nuclear movement.
Apparently either your lying, or you looked at some very weird data.
GMO’s are only “controversial” among a very small slice of the public, and there isn’t a political signal evident in public opinion polling on that topic (i.e., .rightwing fanatics like Alex Jones are proportionally represented). The rightwing talking point that anti-GMO attitudes are disproportionately leftwing don’t stand up to investigation.
I have no idea about “peak oilers” except that I’m reasonably sure that is issue is only a “controversy” among an even smaller slice of the public. You are talking about extreme outliers.
> rejecting it is (was?) actually bi-partisan in the US,
I agree that political leveraging of science is bi-partisan. That has been my point. Where I was pointing out was the problem with your broad characterizations w/r/t how “the left” and “the right” trust in science (or scientists).
There are some broad patterns in play which are suggestive of your broad characterizations, but your characterizations were so broad as to be useless for anything other than cartoonish partisan bickering.
I tend to have more trust in Gouchat’s work..
https://journals.sagepub.com/doi/abs/10.1177/0003122412438225?journalCode=asra
but it’s getting pretty old now and this is more recent:
https://www.pewresearch.org/science/2019/08/02/trust-and-mistrust-in-americans-views-of-scientific-experts/
There’s also this:
https://aeon.co/ideas/what-makes-people-distrust-science-surprisingly-not-politics
> Did you watch the CNN townhall on climate last night? I did.
No, I didn’t watch. I’m not a fan of dog and pony shows.
http://www.culturalcognition.net/blog/2016/12/27/pathogen-disgust-gm-food-and-vaccine-risk-perceptions-a-frag.html
http://www.culturalcognition.net/blog/2017/3/16/trust-in-science-perceptions-of-gm-food-risks-does-the-gss-h.html
http://www.culturalcognition.net/blog/2017/3/19/more-gm-food-risk-data-to-chew-on-compliments-of-gss.html
Anti-GMO is decidedly left-wing.
Here’s the California Green Party on the topic (hardly a right-wing group). Note their shout out to their brethren in Europe for their success in getting bans instituted: https://www.cagreens.org/platform/gmos-cloning
Ask Paul Pukite about peak oilers.
Greenpeace proudly notes they’ve been fighting nuclear since 1971 and will continue. They are not right-wing. https://www.greenpeace.org/usa/global-warming/issues/nuclear/
It’s a shame you missed the “dog and pony show” but you aren’t alone. Most tuned out. A major national and international network devoted 7 hours of prime time programming specifically to the topic of climate change (or their preferred phrasing “climate crisis”). Jack Smith is right, Bernie Sanders laid out the activist-favored action plan in great detail, for 30 minutes right in the middle of prime time on CNN with no pesky tough questions.
jeffnsails said:
“???Exxon, BP, Westinghouse Nuclear, EIA, IEA. You should read the posts by a guy named Paul Pukite.”
I really have no idea what jeffnsails is referring to now. I worked at IBM Watson and my co-author at Bell Labs, and personally have never worked for a fossil fuel or energy company. IBM and Bell were considered commercial research and historically have been praised for all the advances that they have made to science and technology. The big difference between research by these kinds of companies and Exxon or BP is the latter only dipped their toes into the sharing of their findings.
You certainly have a strange view of who contributed to research and scientific advancements over the course of the last century.
Jeff –
>Anti-GMO is decidedly left-wing. Here’s the California Green Party
I know that you’re a rightwing crusader, but do you really think that based on the stances of one activist group (or even a bunch of activist groups), you can characterize the association between political orientation and GMOs?
I gave you access to data that actually informs on the topic.
Unfortunately, that kind of reasoning seems pretty much characteristic of your comments here, so the interesting question for me is whether you actually believe that kind of crap, or you’re peddling it here because you think someone might find it convincing?
So maybe my binary choice of lying or looking at weird data was too simplistic. Maybe you’re just prone towards bad reasoning when your political identity feels threatened?
Based on your logic, we may as well characterize “the right” based on someone like Alex Jones – I’d provide a link but apparently he’s been scrubbed from Google searches.
Jeff,
I’m pro nuclear but I have grave concerns about mixing radioactive material with human error and malfeasance.
I’m also pro GMO. And let me stress the O=Organism=Humans too. We will modify the human gnome but the other half of the ‘Which questions should we not ask” is “and not try to answer”?
So will we, with knowledge and forethought intentionally create a superior human and intentionally validate the concept of racism?
Of course we will because we can’t stop technology. They will be called Uber Sapiens; Smarter, faster, immune to to everything from cancer to the common cold(no vaccines needed), regenerate damaged organs, see in infra-red, smell better than a DEA drug dog, telepathic and can live to 180yrs+.
If we have any empathy or morals left we might use gene-drive to retroactively upgrade the inferior homo sapiens to at least eliminate genetically inherited diseases.
I’m left of centre and not anti-GMO, assuming the usual caveats about monopoly creation [shrugs]…
Jeff…
So you think GMO concerns are left wing. Interesting. Greens keep getting labeled left, but they aren’t. They just happen to be concerned about the environment. This didn’t look nutty to me;
https://www.cagreens.org/platform/gmos-cloning
As far as I know there are no direct health concerns with GMOs. Often there are ancillary concerns like they need more water or some such. However, one fact is that using GMOs isn’t much different that indiscriminately using antibiotics, and that is incredibly bad. Perhaps experts would study that if it was true then, right? There would be data on that?
Ahhh they do, and there is data;
“As of 2005, there were only three reports of insect resistance that “substantially reduced the efficacy of the Bt crops in the field,” according to the release. As of 2016, there were 16 such reports, and in those cases, it took an average of five years for resistance to develop, the study reports.”
https://www.the-scientist.com/the-nutshell/insects-are-increasingly-evolving-resistance-to-genetically-modified-crops-30750
Then.. how about that Roundup ready stuff? That couldn’t result in super weeds could it? I mean farmers have all known that since the 1960’s pesticides cause stronger weeds.. right?
“Twenty-four cases of glyphosate-resistant weeds have been reported around the world, 14 of which are in the United States. Farmers are now back to tilling their farmlands and spraying more toxic herbicides in addition to Roundup in an attempt to control the superweeds spreading across their farmlands .”
http://sitn.hms.harvard.edu/flash/2015/roundup-ready-crops/
GMOs have one other flaw, and that’s that they involve living organisms. That means your neighbor (Donald Big Bucks?), could ruin his farm with GMOs.. but he’d also leave super weeds and super bugs growing all over your land. So you get nothing, but problems with no benefits. Agreed? At least, that’s what the proven facts are as of now.
“…do you really think that based on the stances of one activist group (or even a bunch of activist groups)”
Josh and anOilman, the Green Party is a political party. It self-identifies as left-wing, which is probably why people associate it with the left.
It has global branches – nothing wrong with that – and runs candidates for office.
https://www.theguardian.com/environment/2014/sep/05/green-party-left-uk-politics-caroline-lucas
Jill Stein would be amused that you characterize her as just an activist and not a politician and certainly not of the political left.
Do you really think 7 hours of prime time national news coverage of climate change action plans was a ho-hum non-event? I watched the Biden and Sanders portions and heard the Yang and Klobuchar interviews on the radio. As a result, I’m pretty sure I know why you’re happy people skipped it. 🙂
Jeff –
> Josh and anOilman, the Green Party is a political party. It self-identifies as left-wing, which is probably why people associate it with the left.
It has global branches – nothing wrong with that – and runs candidates for office.
This really isn’t that complicated.
1} You made a characterization of “the left” and an asap iarin with views on GMOs. You provided no evidence to support your characterization.
2} I told you your characterization was wrong.
3) In response, you said you have looked at evidence, and you referenced the view of a particular group, as if it was representative of “the left.” You still didn’t provide evidence to support your statement about “the left” and views on GMOs.
4). So I provided you access to information on opinions on “the left” w/r/t GMOs. Specifically, I provided you with evidence that shows your characterization was wrong. I showed you that the views of the Green Party group you referenced AREN’T characteristic of views on “the left.”. You are trying to generalize based on a haphazard and unrepresentsricd sampling – presumably because doinf so enables you to confirm your partisan biases.
5). So now you are arguing about whether the Green Party holds stances consistent with “the left,” But still haven’t actually supported your assertion.
Again, I’ll ask whether you really don’t see how wreak your argument is, or whther there is a reason you make this argument despite its weakness?
If you don’t grapple with the basic and obvious problems with your reasoning on this issue, then you leave open a strong possibility that you don’t value due diligence to control for your biases more generally in any of the arguments you make.
Jeff –
> Jill Stein would be amused that you characterize her as just an activist and not a politician and certainly not of the political left.
That is also a fallacious argument. What I argued is that you don’t seem to take seriously the need to qualify whether examples are representarive such as to support generalizations. Your argument here shows the same basic error. Obviously, it is possible for Jill Stein to be “of the political” left and for her views generally, and particularly in specific issues, to not he representative of “the left.”
Why do you persist with making such obviously bad arguments? Do you really think your arguments are sound?
And, since it appears, somewhat strangely to be an issue, in full disclosure, I worked at IBM, too, although IBM Federal Systems Division (in Owego, NY), from 1976-1994.
Although there was a sense of proprietariness, IBM was pretty open, and way more open than, say, Google is.
Heretic that I am, I believe holding proprietary information and even patenting things are measures which impede technological innovation.
I very much agree with @anoilman.
I was never concerned about GMOs for eating. I am concerned when the genes of GMO plants escape the field they are planted, and begin to mix with natural populations. That this happens is clear with, according to legal reports, Monsanto, before it was bought, demanding royalties from farmers on adjacent non-GMO farms because Monsanto field agents found some of their genes had “mysteriously” migrated to their fields. (Imagine that.)
Yes, it is true there’s a robust flux of genes in natural environments. And I have no doubt ordinary biological evolution can most likely withstand such an onslaught. What I’m not sure about is what the effects upon a certain species of upright hominid might be if these start showing up here and there. I think caution is advisable.
jeffnsails850: No. Greens started center right in Canada but their policies here just plain centrist here. i.e. NOT LEFT Am I utterly clear about that? Not Left. We actually have a left wing party here, the NDP.
https://en.wikipedia.org/wiki/Green_Party_of_Canada#Principles_and_policies
Back in the early days Greens in Canada got all conservatives to come in and craft their economic policies. Perhaps the real difference between greens and the usual politics is that fossil fuels haven’t paid Greens to make stuff up.
I’d argue that the environment isn’t a right or left thing, since we have Green parties sprouting up like weeds all over the planet. Global Warming is real, that’s science and its a fact. How you react and handle it depends on politics and personal views. As Global Warming grew as an issue various political parties kicked it around labeling it. Its a political pawn which is labeled and used to earn votes. (Isn’t that why Nixon created the EPA?)
@Joshua and others,
It’s amusing to me how desperately people try to impose a total ordering on objects which are inherently really complicated and which, more appropriately, are subject to a multidimensional description. The thing is, though, with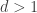 you can’t have a total ordering. Forcing the total ordering means, inherently, that you’ve decided how much more important one aspect is over another, and these not only can be highly subjective, they are highly subjective. Yet, people skip right over this detail and don’t show the work they did to come up with their conclusions. Such conclusions are inherently suspect.
you can’t have a total ordering. Forcing the total ordering means, inherently, that you’ve decided how much more important one aspect is over another, and these not only can be highly subjective, they are highly subjective. Yet, people skip right over this detail and don’t show the work they did to come up with their conclusions. Such conclusions are inherently suspect.
This goes for options or political parties, including the Left-to-Right spectrum. I think trying to do that is a rhetorical flaw.
@ecoquant
Reality is really annoying that way. I guess that’s why there’s a more nuanced spectrum with cuckservatives and libtards?
In engineering we have brain storming sessions where everyone tosses out ideas and just keeps doing that without too much judgement. Maybe we should have a brain storming session and see who thinks what policy is right or left.
Carbon Tax (In Canada: Green\NDP, centrist Left)
Cap and Trade (In Canada Liberal, Centrist)
Heavy Industrial Regulation managed by Central Government (In Canada: Right Wing)
eco –
>It’s amusing to me how desperately people try to impose a total ordering on objects which are inherently really complicated
I’m certainly not immune from over-simplifying for rhetorical purposes and…
> I think trying to do that is a rhetorical flaw.
I’m certainly not immune to rhetorical flaws… nontheless…
Jeff –
This really is confusing to me. I doubt you’re not smart enough to see the vapidness of the argument you’ve made. And I like to hope that you don’t believe that I’m dumb enough to think your argument is worth more than a bucket of warm spit. So what gives?
Is your ideological triggering (i.e., hatred of libz) so intense that you basically turn off your reasoning abilities and thus don’t see what are obvious rhetorical flaws (and so feel that you’re justifying your views by presenting weak arguments)? Are you counting on being able to influence someone who is just not observing your arguments closely (my guess is that explanation would be quite unlikely)?
It isn’t like this is an unusual phenomenon these days (or limited to people of one particular ideological bent), and I really have no excuse for being confused since what you’re doing is very common…but I’m still struggling to figure out what’s going on here.
What explains why you offer such a weak characterization of what “the left” believes, offer no evidence to support your characterization, fail to address contradictory evidence when presented to you, and offer a generalization from a non-representative sample as a justification for your characterization?