
Pat Frank has a guest post on WUWT about breaking the ‘pal review’ glass ceiling in climate modeling. It’s essentially about a paper of his that he has been trying to get published and that has now been rejected 6 times. As you can imagine, this means that there is some kind of massive conspiracy preventing him from publishing his ground breaking work that would fundamentally damage the underpinnings of climate modelling.
In fact, we discussed Pat Frank’s paper here, which was based around a video that Patrick Brown produced to discuss the problems with Pat Frank’s analysis.
I’m going to briefly try and explain it again (mainly based on a part of Patrick Brown’s video, which I will include again at the end of this post). You could consider a simple climate model as being a combination of incoming, and outgoing, fluxes. The key ones would be the incoming short-wavelength flux, the outgoing short-wavelength flux (both clear-sky, and cloud), the outgoing long-wavelength flux (also both clear-sky and cloud) and a flux into the deep ocean. How the temperature changes will then depend on the net flux and the heat capacity, 
![\dfrac{dT}{dt} = \dfrac{[incoming \ SW] - Cloud \ SW - Clear \ SW - Cloud \ LW - Clear \ LW - Q}{C}](https://s0.wp.com/latex.php?latex=%5Cdfrac%7BdT%7D%7Bdt%7D+%3D+%5Cdfrac%7B%5Bincoming+%5C+SW%5D+-+Cloud+%5C+SW+-+Clear+%5C+SW+-+Cloud+%5C+LW+-+Clear+%5C+LW+-+Q%7D%7BC%7D&bg=ffffff&fg=333333&s=0&c=20201002)
So, what has Pat Frank done? He’s considered one of the terms in the above equation (the 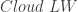
There are a number of ways to explain why this is wrong. One is simply that you should really consider the uncertainties on all of the terms, not just one. A more crucial one, though, is that the error in the cloud longwavelength forcing is really a base-state error, not a response error. We don’t expect it to vary randomly at every timestep, with a standard deviation of 4Wm-2; it is simply that some models have estimates for the longwavelength forcing that is quite a bit different to what it is observed to be.
So, what is the impact of this potential discrepancy? Consider the equation above, and imagine that all the terms are close to what we would expect from observations. Consider running the model from some initial state and assume that the incoming short-wavelength flux, and the atmospheric compostion, are constant. Also, bear in mind that some of the fluxes depend on temperature, 

Now, consider rerunning the simulation, but with a slightly different longwavelength cloud forcing. Again, if we run it long enough, it will settle to an equilibrium state, in which the fluxes balance, and the temperature is constant. However, since the longwavelength cloud forcing is different, some of the other fluxes will also be different, and the equilibrium temperature will, consequently, also be different. There will be an offset, compared to the first simulation, but it won’t grow with time simply because one simulation had a different longwavelength cloud forcing compared to the other.
So, that there is a discrepancy between the longwavelength cloud forcing and observations does not mean that this implies an error that should be propagated at every timestep (as Pat Frank claims). It mainly implies an offset, in the sense that the magnitude of this discrepancy will impact the equilibrium state to which the models will tend. Anyway, I’ve said more than I intended. Patrick Brown’s view – which addresses Pat Frank’s error propagation suggestion – is below, and goes into this in much more detail than I’ve done here.

The hubris, it boggles.
Hmm, err, so I have been thinking about the Unabomber, this always occurs during my visits to the WUWT? website.
As I understand it, his paper was published in The New York Times and The Washington Post.
I would suggest looking at Willie Soon’s or Nicola Scafetta’s journal publications. Get those two on board as coauthors and it’s a cinch for publication in The Journal of Atmospheric and Solar-Terrestrial Physics.
Do deniers eat their own kind?
For some odd reason, Frank is thinking about Russians, Everett:
> With the near hopelessness of publication, I have decided to make the manuscript widely available as samizdat literature.
A defining feature of samizdat is that it was clandestinely printed, of course. Further down he “outs” the reviewers who rejected his manuscript, immediately requesting of the WHUTTers to not “contact or bother any of these gentlemen”.
Pure class.
The comment thread is delicious. Frank responds to Nick Stokes:
> No, I don’t Nick. You’re proposing that ±16°C is a physically real temperature. It’s an uncertainty statistic. An ignorance measure. It’s not physical error.
So … shouldn’t this “ignorance measure” *not* be expressed in physical units?! KiloWHUTs perhaps?
Quote from Pat Frank (circa 2011) …
“I had a discussion about this point at WUWT with a climate scientist posting as EFS_Junior.”
Well then, EFS_Junior would be me, but you all can call me JUNIOR (yes, all caps are a WUWT? requirement, TYVM) and no, IANACS, I just play one on the internetwebs.
Pat Frank then links to his, and my rejection of, his sqrt(n) error propagation nonsense …
… and continued here …
January 20, 2011 is only three months short of SEVEN YEARS!!! 😦
Note to self: Google search EFS_Junior Pat Frank
Pat Brown says the +/_ average was time invariant?
I have it on good authority,
“He averaged 20 years of data, and said the average was 4 W/m2/year, not 4 W/m2.”
that it was a yearly, hence time dependent average.
Does that alter his argument somewhat?
4 W/m2/year, is very close to the forcing of a doubling in CO2 with no feedback, round up to a 2C degree variability in temperature possible per year with the current available fluctuations in cloud cover. A remarkably large range of noise to screen out subtle climate signals from in the short term, if true.
Is it true ?
Being nonscientist I don’t know the peer-review or publishing process and am hoping someone can help me understanding something. Regarding “about a paper of his that he has been trying to get published and that has now been rejected 6 times.” –
When a scientific paper gets submitted for review, it’s give to selective expert reviewers who read the article and give their assessment of the papers quality and contents, then they report their thoughts to the publisher. When a paper gets rejected, I would assume that the various critiques are shared with said author.
Is that reasonably accurate? If it’s basically correct, then . . .
What’s it mean for a paper to be rejected 6 times?
Perhaps that the author refused to accept and process legitimate critiques offered?
How often do scientists ignore critiques and simply submit the same paper to a different venue?
How often do reviewer critiques get processed and reflected in changes and improvements to papers that had previously been rejected?
Citizenschallenge,
At most journals papers can be rejected by an editor before review, and a reason is usually supplied, e.g. Nature editors reject a lot of papers because they don’t think they’re of wide enough interest. Or if you submit a paper on the feeding habits of geese to an astrophysics journal you’ll be told it’s “out of scope”.
If it’s rejected in review, you get to see the reviews.
“What’s it mean for a paper to be rejected 6 times?”
Well, it means six different journals have told Frank it wasn’t worth publishing.
“Perhaps that the author refused to accept and process legitimate critiques offered?”
Depends, some will have been summarily rejected (out-of-scope, obvious nonsense, not interesting enough, etc), and some will be rejected if the author cannot or will not make the requested changes.
“How often do scientists ignore critiques and simply submit the same paper to a different venue?”
Often. But I can’t put a number on it. I’ve done it myself with a few papers, where I could not make the requested changes (it’s always reviewer number 3 asking for more experiments…) or when they just did not consider it a sufficient advance to be worthy of the journal. And once because they told me “this is all already well known, so why should we publish this?”, after we explained in detail this was all already well known, but apparently not to the people publishing in this journal, because you have 50+ papers making these basic mistakes.
“How often do reviewer critiques get processed and reflected in changes and improvements to papers that had previously been rejected?”
More often than the above, at least in my experience.
angech,
No, because it’s not 4W/m^2/yr.
There does seem to be a certain mystique about the whole peer-review process.. having gone through it (once only, mind) my impression was that it was not really demanding enough and any half-reasonable paper can get published..
Getting rejected six times can only mean that either you are not bothering to read and incorporate feedback from review comments into improving the papers, or there is something glaringly wrong with the paper that it would be fundamental to remove.. and for some reason you need telling six times. It would, after all, take quite a conspiracy for six sets of reviewers to all deliberately and falsely reject a paper from the same reason.
Or the author of the paper could be a misunderstood genius who is completely right and all the fools who review his or her paper are wrong for the same reason. That happens a lot, too.
Andrew,
Yes, this is my impression too (having published quite a bit more than one 🙂 ). If you really want to get a paper published, you normally can. Partly, reviewers don’t have the time to go through every aspect (and probably shouldn’t). There’s also a sense that it’s better to publish a controversial paper and let the community respond, than not. If a paper really does get rejected multiple times, it probably means that it’s really, really bad, not that it’s so controversial that noone wants it published.
Frank apparently also thinks he had a debate with Gavin Schmidt and won, because Gavin in the end had to explain some basic math that Frank got all wrong (but, of course, could not acknowledge).
And he apparently had even more rejections (3), but at the Editorial stage, including two from non-climate journals.
For some reason I actually read comments on that WUWT thread. As depressing as the experience was, I thank ATTP for pointing out http://vixra.org/
Marco,
I noticed that. Odd, both because he clearly did not and because normally one doesn’t really engage in scientific discussions in order to win.
Szilard,
My pleasure, although it was actually Michael Brown who suggested that, on Twitter.
I’m trying to publish papers that are full on greenhouse but challenge the notion that warming occurs in situ in the atmosphere and maintains that it is not gradual on decadal timescales. Try that – it’s not easy. Putting up abject rubbish is much easier because there’s a market for it. Try challenging the status quo.
This and the previous post are related because they try and treat the atmosphere as 1-dimensional with respect to forcing, which it is not. The above equation is junk – it supposes that the radiation-temperature transfer is equal for shortwave and longwave and that feedbacks are instantaneous. They are not. The pea and thimble trick with the 4 W/m2 is just icing on the cake. (SW and LW processes are different – they are treated the same when calculating effective radiative forcing, which is a long-term averaged factor, but this misses some important dynamics).
For the previous post, Arrhenius did recognise the temperature profile of the atmosphere and he continually referred to the temperature of the ground. He calculated that about 40% of longwave radiation had been captured within about 230 m of the surface. This is partly based on experimental obs by Langley, I think (would need to check back to make sure). He also recognised that the height of emission would rise. People forget that these early papers on greenhouse were all based on experiment, observation and some theory. They are very impressive. The current greenhouse effect paper from Schmidt et al. (2010) also attributes a large amount of the current greenhouse effect to water vapour (occurring lower in the atmosphere) and clouds (higher up) with CO2 playing a modest role. But without the CO2, neither the water vapour nor the clouds would be there.
The big issue, is that there is a delay between when reflected LW radiation is captured by ghgs and when it warms the atmosphere if GHGs are increasing. This is because all not captured by sinks (ground, ice and snow melt), goes back into the shallow ocean, which acts as a store. The deep ocean is a sink, but it acts somewhat independently of shallow ocean-atmosphere interactions, though they do modify each other. The atmosphere does not maintain its own temperature independent of the ocean surface – it cannot, lacking both the thermodynamic capacity and conductivity. The land is passive, absorbing little and reflecting a lot.
Current thinking is that 93% of the added heat since about 1955 has gone into the ocean and a small amount has been retained in the atmosphere, ocean uptake limited by some kind of ocean heat uptake efficiency. This isn’t the case. Everything that can go into the ocean, does. It becomes part of enhanced climate variability. That’s when things get interestin,g because this idea treats natural and anthropogenically-generated heat as a single entity, rather than separate entities in a statistical signal-noise relationship where the signal is a monotonic trend. This heat is dissipated by the climate system to the top of the atmosphere and the poles by decidedly nonlinear processes, largely involving decadal climate variability.
Once the additional heat is absorbed in the shallow ocean, steady state conditions are maintained until the surface state becomes unstable with respect to the TOA state, and regime change causes a step-like shift to warmer conditions capable of doing the work that can get some of that heat to the top of the atmosphere and the poles. (The main store is the western Pacific Warm Pool, which becomes unstable once it holds too much heat, it basically acts as a heat engine). Only once in atmosphere warms can cloud feedbacks occur and they do. So the uncertainty of cloud feedbacks in the models is of secondary importance for the causal process involved in greenhouse warming. It’s critical for understanding sensitivity, though.
Roger,
A bit strong maybe? It was just an illustration of energy balance, to highlight two things.
1. You can’t do uncertainty analysis by considering the uncertainty in only one term/process.
2. Some of the uncertainties are in the base state, which will produce an uncertainty (or, an offset) in the equilibrium state, but won’t produce an uncertainty that you propagate in the way that Pat Frank suggests.
This seems like arguing about how we choose to describe things, rather than what we actually think is happening. When people say 93% has gone into the ocean, what they mean is that if you were to determine the total amount of excess energy that has entered the climate system and then compare that to how much has gone into the oceans, the ocean component would be 93% of the total. The argument is not that the excess energy was somehow sub-divided, with 93% specifically going into the oceans, and 7% going elsewhere.
My own personal way of thinking of this is that we have an planetary energy imbalance and that this excess energy enters the system and is then distributed in a manner that depends on the various dynamical processes, probably dominated by the oceans. This seems reasonably consistent with what you’re suggesting, but I’m not entirely sure.
I haven’t had time to watch Patrick Brown’s 38 minute discussion of the flaws of Frank’s approach or glance at Frank’s manuscript (also don’t want to pad his download count), just skim through this discussion.
Would a fair analogy be that since an individual’s metabolic rate varies from day to day and since daily caloric intake can only be estimated to a certain precision, any attempt to model weight gain or loss is pointless since everyone ends up weighing 800 lbs?
“my impression was that it was not really demanding enough and any half-reasonable paper can get published..”
Yes, that is my impression also (having published a fair bit). Peer review is only really a basic sanity check, it is unwise to view it as some meaningful validation of the correctness of a paper. It is only the start of peer review, the more important test is the reaction of the research community. Generally if a paper is good, then it will get well cited (by the standards of that field) and if it is bad, then the usual fate is for it to be largely ignored (although sometimes good papers get ignored and bad papers get cited, so it is a rather noisy indicator). It would probably not be a good use of researchers time to make peer review rigorous enough to be a worthwhile indicator of correctness as it would mean we spent all our time peer reviewing, rather than actually doing research. Also sometimes an idea comes along that isn’t properly appreciated at the time, but may spur progress if discussed, so allowing any half-reasonable paper to be published is probably a good compromise.
The paper that contains probably my best work to date (or at least the bit I currently dislike the least*) was rejected by three journals before it was finally published (still by a good journal). The final paper was over twice a long as the first version from addressing the comments made by the reviewers of the previous journals (I think that made the paper a bit long and less well focused, but I did it anyway). Being rejected a few times doesn’t necessarily mean the paper is bad or uninteresting (in my case there were no technical problems identified with the methodology IIRC), in my case I think it is because I didn’t make the case clearly for a reader that wasn’t me. Sadly it hasn’t been cited much, which is a pity as it works really well in practice 😦
The real problem here is a really poor attitude to the reviewers comments. If you repeatedly have the same technical flaws pointed out by multiple reviewers, then it is ridiculous hubris to think it is they that are wrong rather than you, especially if you are not a researcher in that field. ISTR reading a paper about peer review that points out we should take the reviewers comments very seriously as we are getting for free the advice of experts whose time we could not afford to buy!
* familiarity breeds contempt and nobody knows my research better than I do!
ATTP,
Ok – I didn’t realise that that was your equation, but that construct is what Frank is banking on. The only way that such an equation can be resolved is over long-term time scales, but by doing that, important processes that describe how warming occurs are overlooked. It is impossible to debate cloud feedbacks on those terms. Sorry, I thought that’s what this post was about.
And it is a heat capacity equation, so I’ll stick to my guns. There is no ocean, and we are not on Venus nor Mars
“I’m trying to publish papers that are full on greenhouse but challenge the notion that warming occurs in situ in the atmosphere and maintains that it is not gradual on decadal timescales.”
ISTR having a look at your work, but not being confident I knew exactly what you meant by “in situ” (but then again I am not a climatologist).
“This and the previous post are related because they try and treat the atmosphere as 1-dimensional with respect to forcing, which it is not.”
All models are wrong, but some are useful. The blanket model of the greenhouse effect is a useful starting point in explaining e.g. why the GHE doesn’t violate the second law of thermodynamics, without being a quantatively useful model. I agree that it would be better if the basic “effective height of the radiating layer” model were used more often. ISTR John Cook gave a talk a year or two ago where he asked the audience if they could explain the GHE mechansim, without there being many volunteers, which perhaps suggests there is work to be done.
Roger,
It’s actually what Patrick Brown put in his video to try and explain why Pat Franks’s reasoning was wrong (that is really the point, not to try and present some kind of alternative climate model).
Actually, the is meant to be the heat capacity of the upper ocean/land/atmosphere, and the
is meant to be the heat capacity of the upper ocean/land/atmosphere, and the  represents energy transfer into the deep ocean. I don’t think there’s anything wrong with it from the perspective of illustrating the basic energy fluxes. It wasn’t really intended to do anything other than that.
represents energy transfer into the deep ocean. I don’t think there’s anything wrong with it from the perspective of illustrating the basic energy fluxes. It wasn’t really intended to do anything other than that.
Roger,
I’ll respond to this too, because I do think this somewhat misrepresents the intent of the posts. The posts are both trying to explain something and – to do so – have used simplified descriptions of the processes. This isn’t because I actually think that everything is this simple, it’s because I don’t think there is an easy way – in a blog post aimed at a more general audience – to include all the complexity. You can, of course, disagree and are free to come up with more complex explanations, which may even explain things more clearly than I have done. You might, however, want to pay due diligence to what I think I may start calling my “iron law”, which is nicely illustrated by the figure below.
Magma,
I think a fair analogy might be trying to determine how someone’s weight is changing with time, but there being an uncertainty in their initial weight and then assuming that one should propagate this uncertainty.
angech,
W/m2 is already a time-based unit – it’s Joules per second per metre squared. W/m2/year would be a unit of acceleration. The Earth accumulating at 4W/m2 would mean that net (inflow-outflow) energy into the Earth system is occurring at a constant (or average) rate of 4 Joules per second for every square metre. That could be the rate over 1 day, 1 year, 1 Century etc. If Frank talked about his propagation in terms of Joules instead of Watts that small part would make some sense (though the rest of remains equally nonsensical) – say you had +/-4W/m2 uncertainty and a time step of 1 second, the uncertainty in the number of Joules after 2 seconds would indeed increase to +/-8 Joules, after 3 seconds +/-12 Joules etc. However, the uncertainty in rate (Watts) remains constant at +/-4W/m2 through those time steps.
I think mixing up implications of Joules and Watts could be part of Frank’s confusion.
Wasn’t me, ATTP :-). It was Magma.
[Mod: fixed, thanks]
…Once the additional heat is absorbed in the shallow ocean, steady state conditions are maintained until the surface state becomes unstable with respect to the TOA state, and regime change causes a step-like shift to warmer conditions capable of doing the work that can get some of that heat to the top of the atmosphere and the poles. (The main store is the western Pacific Warm Pool, which becomes unstable once it holds too much heat, it basically acts as a heat engine). Only once in atmosphere warms can cloud feedbacks occur and they do. So the uncertainty of cloud feedbacks in the models is of secondary importance for the causal process involved in greenhouse warming.It’s critical for understanding sensitivity, though. – Roger Jones
Bold mine, and it’s why I am in the RogerJones camp. Politically, it’s a far better argument. Right now the propagandist are looking for hiatuses under every rock. Because they know they can trick themselves and the public with hiatuses.
I’m not out of the Roger Jones camp. I simply think there are occasions when its best to present simple representations of what is happening, and occasions when it’s appropriate to describe more of the complex dynamics. I agree that addressing claims of hiatuses will require a better understanding of the coupling between the oceans and the atmosphere. Trying to explain why Pat Frank is wrong, however, does not really require this.
Hmm, reading Frank’s manuscript and following the references it seems like there are a series of basic reading comprehension errors which have, ironically, propagated into the wildly inaccurate work he’s produced.
The all-important +/-4W/m2 figure is referenced as coming from Lauer and Hamilton 2013, which states:
So, 4W/m2 refers to the RMSE of the CMIP5 mean versus obs for LCF (Longwave Cloud Forcing). That’s a bit confusing because I thought Frank was presenting it as the spread of global average error over the model ensemble, but it’s actually the average spatial error (i.e. comparing grid cell to grid cell) between observations and the CMIP5 mean. RMSE is sign-independent so it would actually be plausible for spatial RMSE to be 4 with zero global average error. In practice this perhaps isn’t so important because there is an inter-model spread in global LCF (not sure of what magnitude), even though he has botched getting there.
Then, in translation, an important leap occurs in terms of how Frank represents this value:
To be honest, I have no idea what the “per model-1” bit at the end is intended to mean, but it’s clear that he is already representing the +/-4W/m2 in terms of an annual increment, as angech suggested he was. Two paragraphs later he even compares the +/-4W/m2 to a 0.035W/m2 year-1 increase in greenhouse gas forcing. Why isn’t immediately obvious since the paper cited is specific that it refers to multiannual climatologies (20 years specifically), but I suspect it’s a misunderstanding of the fact the paper also refers to it as an annual average, meaning as opposed to representing seasonal climatologies.
Yes aTTP, I got that when I read your article. All I know is October just heated up a bunch, and should hang on to end up a bit warmer than September, which means 2017 still has a shot at finishing 2nd warmest.
For anybunny wondering what reviews of scientific papers look like, the EGU runs an open review process and you can look at a variety of them. When papers pass open review there is a further step so you can also look at the correspondence btw the editor and the authors.
https://www.atmos-chem-phys.net/
Dikran said
On line citation indicies have ruined this, because it is easier just to pull down a list and garbage it into the references rather than look in your file for things that are relevant and useful.
Mathematics is interesting bcs publication requires line by line review. There is something out there now which is so difficult and done by somebunny everybunny agrees is a genius but they can’t publish it because nobunny can check it.
I don’t think it has ruined it, but that is always an issue. It is interesting to look at some of the papers that have cited you own and see how many do the thing you were arguing against ;o).
Maths is indeed an exception, where there is value in publications being checked more thoroughly for correctness.
Eli said:
One of the recent Field’s Medal winners in math died this month. At one time he said this about the state of theoretical research:
Have to start simple or come up with something clever.
Apparently “Asia-Pacific Journal of Atmospheric Sciences” rejected Frank’s submission. Frank invents a narrative of “bias” to explain this rejection:
“Asia-Pacific Journal of Atmospheric Sciences. Songyou Hong, chief editor; Sukyoung Lee, manuscript editor. Dr. Lee is a professor of atmospheric meteorology at Penn State, a colleague of Michael Mann, and altogether a wonderful prospect for unbiased judgment. […] I hope she was rewarded with Mike’s appreciation, anyway.”
Of course, Frank’s narrative makes no sense, since Asia-Pacific Journal of Atmospheric Sciences previously published papers from contrarians. This includes papers from Lindzen and Spencer:
Lindzen: “On the observational determination of climate sensitivity and its implications”
Spencer: “The role of ENSO in global ocean temperature changes during 1955–2011 simulated with a 1D climate model”
So as with other paranoid conspiracy theories about peer review, Frank’s claims remain un-tethered to reality.
“Denialism is a process that employs some or all of five characteristic elements in a concerted way. The first is the identification of conspiracies. When the overwhelming body of scientific opinion believes that something is true, it is argued that this is not because those scientists have independently studied the evidence and reached the same conclusion. It is because they have engaged in a complex and secretive conspiracy. The peer review process is seen as a tool by which the conspirators suppress dissent, rather than as a means of weeding out papers and grant applications unsupported by evidence or lacking logical thought.”
https://academic.oup.com/eurpub/article/19/1/2/463780/Denialism-what-is-it-and-how-should-scientists
RE: Asia-Pacific Journal of Atmospheric Sciences …
“UAH Version 6 global satellite temperature products: Methodology and results”
Spencer, R.W., Christy, J.R. & Braswell, W.D. Asia-Pacific J Atmos Sci (2017) 53: 121.
RE: Conspiracy Theorist Pat Frank…
“Manuscript editor … is a climate modeler. His career would have been
negatively impacted were the manuscript to be published.”
paulski0 says: October 24, 2017 at 12:52 pm angech,
“W/m2 is already a time-based unit – it’s Joules per second per metre squared. W/m2/year would be a unit of acceleration”
As ATTP Said to Roger above about the equation, I similarly took the comment from the video start, at thge 3rd dot point
Pat Brown wrote the +/_ 4W/m2 average was time invariant?. Thanks for clearing up the confusion and your subsequent comment further down.
Roger,
” there is a delay between when reflected LW radiation is captured by ghgs and when it warms the atmosphere if GHGs are increasing.
This is because all not captured by sinks (ground, ice and snow melt),
goes back into the shallow ocean, which acts as a store.
The deep ocean is a sink, but it acts somewhat independently of shallow ocean-atmosphere interactions, though they do modify each other.
The atmosphere does not maintain its own temperature independent of the ocean surface – it cannot, lacking both the thermodynamic capacity and conductivity”
The big issue, the delay that you speak of , is at the heart of a lot of our climate disagreement, the fundamental nature of reality.
My problem is resolving the concept of a heated object in balance with the concept of a delay in transmission of energy fluxes. For instance heating up a metal sword in a furnace. Obviously initially energy is going into the sword that is not radiated out and if you pull the sword out of the fire [night time] the energy going out is greater than that coming in.
I guess the sword is acting as a heat sink while heating up, storing energy, and that this is not instantaneous so the time to heat up, different for different mediums and densities has a definition. As does heat loss.
Could you explain the conundrum, that the atmosphere lacking thermodynamic capacity and conductivity, hence being highly reactive to energy input, does not heat up to the temp specified by Arrhenius each day to the level dictated by the CO2 level?
1. “The atmosphere” is not homogenous, varying hugely from the equator to the poles. So your question is probably only meaningful if posed to the atmosphere at a particular place on the earth’s surface
2. That small part of atmosphere (consider a cube for argument’s sake) has boundaries.
a) at the base, it will exchange heat with either ocean or land by radiation, evaporation and convection. Both ocean and land have appreciable heat capacity.
b) at the top, it will lose heat to space by radiation.
c) at the sides, it will exchange heat and mass with adjacent parts of the atmosphere via the action of winds
All of these exchanges are variable, and not equilibrium processes. Accordingly, the atmosphere is not at an equilibrium* temperature.
*[putting aside thermodynamic definitions of “equilibrium” and substitute “steady state” or “quasi steady state” according to your degree of pedantry]
The 3rd-quarter OHCA should be published in the next few days. Up or down, or about the same? Depends.
One would think that Pat Frank would have slunk away in abject ignominy after Patrick Brown eviscerated him at the beginning of the year. Apparently not…
Which leads to an hypothesis – the refractory period for a Dunningly-Krugered physics-denying pseudoscientific woo-tian after they suffer a palpable rebuttal is approximately nine months, give or take. Of course with a pilot sample size of n = 1 the estimate may be out, but it begs the question about how frequently these useful idiots will recycle their faff, knowing full-well that it has been debunked, and what is the underlying psychology that permits them to do so without the pangs of conscience to trouble them.
Regarding PF’s argument and having just watched Patrick Browne’s video on it – Would I be correct to think that if one propagates +/- 4W/m^2 through the model iterations then that would be an imbalance that needs to be addressed by applying a similar +/- 4W/m^2 of SW absorbed at each iteration?
Would that make it a correct way to proceed?
Tony,
In a sense, yes, it would be the uncertainty in the net radiative imbalance/forcing that would matter. Even that, however, is – I think – not what one would propagate in time, because an uncertainty in the radiative forcings would imply an uncertainty in the equilibrium state (to which the system will tend) not an uncertainty that will grow with time. The ± 4 W/m^2 is also due to different models having different longwavelength clouds, not a representation of the uncertainty in the longwavelength cloud forcing in an individual model.
“One would think that Pat Frank would have slunk away in abject ignominy after Patrick Brown eviscerated him at the beginning of the year. ”
Sorry, but Gavin Schmidt did so several years earlier already (the debate Frank claims he won…). Nothing stops the crank from going on and on and on (see also Peter Ward, who still peddles his “ozone depletion = cause of warming” claim).
Indeed.
Pat Brown wrote the +/_ 4W/m2 average was time invariant?
It’s not a question of whether it’s time-invariant (i.e., not a function of time). The price of gas is a function of time, but it’d still be pretty bad to get the price of gas confused with the change in the price of gas per year.
If the average price of gas is $3/gallon (as averaged over the last 10 years)… does that mean the change in the price of gas is $3/gallon/year? No, very much no.
Yes, Nick Stokes tried to make that point. It didn’t – as you can imagine – work.
@ ATTP, from Pat Frank’s reply to Nick Stokes’ comment:
I have nothing to add.
Such a radical insight seems worth repeating.
And not one of the Wattites picked up on that.
I’m reminded of a filmed lecture where Richard Feynman talked about the volumes of mail he and other physicists would get from cranks ‘disproving’ quantum mechanics, general relativity, the first and second laws of thermodynamics, etc.
These days they don’t even need a stamp.
And I forgot to mention Frank’s comments on “Science Bulletin” rejecting his submission:
“Science Bulletin. Xiaoya Chen, chief editor, unsigned email communication from “zhixin.” […] An analysis that invalidates every single climate model study for the past 30 years, demonstrates that a global climate impact of CO2 emissions, if any, is presently unknowable, and that indisputably proves the scientific vacuity of the IPCC, does not reach a priority sufficient for a full review in Science Bulletin. Right. Science Bulletin then courageously went on to immediately block my email account.”
Would that be the same “Science Bulletin” that published a couple of fairly poor “papers” from Monckton, Soon, Legates, and Briggs?:
“Why models run hot: results from an irreducibly simple climate model”
“Keeping it simple: the value of an irreducibly simple climate model”
I’m pretty sure those two aforementioned “papers” made serious criticisms of the model used by the IPCC, as Frank claims to. Yet Science Bulletin published those two “papers” anyway, while rejecting Frank’s submission. So maybe Frank should consider that the problem may be with his submission, if it’s worse than something Monckton co-authored.
I just read the leaked list of ‘climate scientists’ that the Heartland Institute submitted to the EPA for the Trump administration’s apparently stalled Red Team exercise on anthropogenic climate change. Pat Frank is on it, so I’m not quite hijacking this thread. http://climateinvestigations.org/heartland-institute-climate-red-team/
If anyone’s interested in a long-term bet, I’ll give 2:1 odds that over half of the 145 individuals on the list will be dead within ten years. Would-be bettors should note that Roger Pielke Jr. (48) and Willie Soon (51) appear to be the youngest on the roster by many years.
“Roger Pielke Jr. (48) and Willie Soon (51) appear to be the youngest on the roster by many years.”
May be difficult for young deniers to get placements with all the pressure and all. Does not mean that they are not there only that one needs to get some security before being able to buck the establishment.
Quite a few real scientists with years of experience and papers from the look of it.
“I’ll give 2:1 odds that over half of the 145 individuals on the list will be dead within ten years.”
Why?
Climate change is not happening that fast, is it?
angech,
I think he is just referring to their typical ages, which is high enough that a reasonable numner
“Quite a few real scientists with years of experience and papers from the look of it.”
One of the most ‘qualified’ one’s (Judith Curry) has already expressed she ain’t going to be on no Red Team with B-list and agendra-driven people. Weirdly enough, she didn’t quite like working with an A-list person either (Richard Mueller), but that was when the results came in.
@-angtech
“Quite a few real scientists with years of experience and papers from the look of it.”
There is a common pattern to the contrarian scientists when any controversial theory develops in a field of research. Consider the history of evolution, plate tectonics, general relativity or quantum mechanics. All had a rump of dissenting real scientists with years of experience and papers.
The common characteristic was that they were students before/when the ‘new’ idea was a hypothesis. As the evidence accumulates and the hypothesis becomes a theory, the room for dissent shrinks. Only those that formed their views BEFORE the cumulative evidence (CO2 levels, sea level rise) was obvious, seem able to maintain their original doubts.
The result has been that the few real scientists that doubted evolution, plate tectonics or GR shrunk because all the new entrants to the field learnt the new theory.
The remaining contrarians were then those without direct knowledge and experience of that field, (engineers? medics!?) and/or those with a very strong theological or ideological axe to grind.
In all three cases the US was the last stronghold of dissenting scientists. Note the involvement of Arvid Reuterdahl with the support of Henry Ford.
http://mediaimposible.blogspot.co.uk/2010/11/einsteins-sceptics-who-were-relativity.html
“THIS world is a strange madhouse,” remarked Albert Einstein in 1920 in a letter to his close friend, the mathematician Marcel Grossmann. “Every coachman and every waiter is debating whether relativity theory is correct. Belief in this matter depends on political affiliation.”
Yup. Reality is extremely pressing.
Both blue team and red team need to be composed of researchers experienced enough to have a broad appreciation of the field as a whole. I’m not sure I would expect to see large numbers of candidates in their twenties and thirties. The real problem is the paucity of good skeptic candidates, of any age, which is perhaps just further evidence of the evolution of a consensus as the science matures.
Assume Pat Franks correct. Then if you ran a model with constant atmospheric composition the annual variation should accumulate.
So every once and a while the pall of Alzheimer’s lifts and Eli does remember back when he read a certain paper by someones called Hansen, Fung, Lacis, Rind, Lebedeff, Ruedy, Russell, and Stone, 1988: Global climate changes as forecast by Goddard Institute for Space Studies three-dimensional model. J. Geophys. Res., 93, 9341-9364, doi:10.1029/JD093iD08p09341.
They ran a century control run with greenhouse gas concentrations fixed at about the 19858 values with heat exchange across the maximum mixed layer depth in their ocean model so that it would respond quickly to changes in natural variability, and they compared the variability to that observed between 1951 and 1980
Somebunny not banned there might go over and point this out to Pat and Willard Anthony
It is unfortunate that the PF paper rejections -apparently – did not include reasons for its rejection from editors or reviewers. That seems to have allowed the idea that it might be because of the subject, rather than the quality.
Now that he has put it online however it has recieved substantial review, a process some regard as better than ‘pal review’. Including by people familiar with mainstream climate science.
Now that he is aware of what the mainstream science regards as the error(s) in his arguement perhaps he can avoid the errors and still maintain his claims, or include an explanation of why the mainstream critique is mistaken.
Failing that, he coulds always claim victimhood and in a striking similarity with the opponents of General relativity…
” …it was easy for Einstein’s opponents to see themselves as victims rather than aggressors. In their interpretation of reality, the mere existence of relativity theory and the non-acceptance of arguments against it qualified as an attack on them.”
I don’t know whether to laugh, or cry.
Obviously PF is dissin’ the room. meters/person/room and now we’re gettin’ somewhere.
‘Where’ that is I have no frickin’ clue.
So Eli boiled it down further and left a note. Let us see if they are in favor of open discussion
————————————–
Let Eli make this simple. Take some parameter B. Nick Stokes is saying that three values used for annual runs are
1. 2.0
2. 2.1
3. 1.9
Pat Frank is saying the three values must be
1. 1.0
2. 2.1
3. 2.9
In both cases the average is 2.0. Nick says this is an average of 2.0. Pat says this is an average of 2.0/yr
Now you would think that if Pat Frank were correct, running a model without changing the atmospheric composition would give wildly diverging results as the number of years increased. But GCMs don’t behave that way, and indeed doing such runs is a basic test of the model and tells something about the unforced variability in the model on different time scales which can be compared to the observed natural variability on those time scales.
”
The average height of people in a room is meters/person, not meters.
”
If there is large number of people with multiple personality disorder in a room, their average height approaches zero.
The average height of people not in a room is measured in Potrzebies.
“It is unfortunate that the PF paper rejections -apparently – did not include reasons for its rejection from editors or reviewers. ”
It did. The three journals that rejected it at the Editorial level gave reasons that are best described as “wrong journal, not the research we’re interested in”. For the other journals the reviewers pointed out major flaws. It’s just that Frank just doesn’t get it. For example, Frank claimed to have “won” a debate with Gavin Schmidt, in which Frank had to admit he used an arbitrary start-CO2 concentration of 1 ppm (well below the level where logarithmic effects are relevant) and where the latter value was crucially important for his “base value” for his model. So, why not choose 0.1 ppm, Gavin asked? No answer.
Kevin O’Neill,
I’m calling meters/person/room/averaging/question/person/room/planet/universe
“The average height of people in a room is meters/person, not meters.”
Average weight of people is Kg/person3
Yes, I know that this is all quite humorous. but …
https://upload.wikimedia.org/wikipedia/commons/d/da/Random_Walk_example.svg
https://en.wikipedia.org/wiki/Random_walk
What PF is doing is usually called a 1D random walk.
In his case, this leads to a gaussian (or normal) distribution with mean equal zero and sigma =a*sqrt(n) (skewness =0 and kurtosis = 0), where a = 4. I’ve checked this out numerically (10,000 steps and 100,000 realizations).
Note to self: Excel is a dog.
See also …
https://en.wikipedia.org/wiki/Residual_sum_of_squares
https://en.wikipedia.org/wiki/Root-mean-square_deviation
So as n approaches infinity, square root of n also approaches infinity. There are no restoring forces or conservation laws that constrain this foolishness.
Long story short?
No field of engineering or science would be immune from this very foolish approach. All models are wrong, and only get wronger, and then wrongest, the longer one goes.
So don’t drive that car, or use your computer, or airplane or train, because according to PF they would all blow up or freeze below absolute zero.
The *.svg image didn’t work, so here’s a *.png hope this one works …

“Now you would think that if Pat Frank were correct, running a model without changing the atmospheric composition would give wildly diverging results as the number of years increased”
Eli.
Could not would.
You know the maths and statistics better than I but you persist in using a wrong assertion.
No matter the divergence,as long as it is random and around a mean variance, the end result as the number of years increased would be spaghetti with the largest number of results still centred around the mean.
Strongly converging would be the mathematical term for the overall result.
Wildly diverging would only apply to the much, much smaller number of results that diverge in opposite directions from the mean
Eli writes: “Now you would think that if Pat Frank were correct, running a model without changing the atmospheric composition would give wildly diverging results as the number of years increased.”
Eli didn’t read PF close enough. PF believes that uncertainties, model output, and physical properties are all essentially divorced from each other. Read PF’s list of accusartions against climate scientists again.
There’s a lot of gibberish here, but if one tries to be charitable and search for meaning, it still leads one to believe there’s a lot of gibberish here. But, #12 is at least I believe, attempting to address the point that Eli is making; PF simply doesn’t believe that a relationship should (or can?) exist.
This would be news to anyone that has tried to gather data and calculate uncertainties. I have news for PF: When used properly, math works. Let’s use as an example a simple Liquid-In-Glass thermometer with a calibrated accuracy of ± 2% and a calibration uncertainty of ±1% (at k=2 representing a 95% confidence level).
Next we’ll take an oil bath that we have lying around whose accuracy is known to within a few °mK and soak the thermometer in the oil bath with the temperature of the bath set to 373.15°K (100°C). We wait a bit an we record the thermometer’s reading. We have time on our hands so we remove the thermometer, let it cool down, then repeat the whole process until we have 100 measurements.
In looking at the results we expect several things: 1) The measurements should closely resemble a normal distribution. Two-thirds of the measurements should be within a little more than 1°K of the ‘true value.’ About 95% of the results should be within 2.2°K of the ‘true value.’
If our results don’t match these simple sanity checks, then Houston we have a problem. Could be our thermometer is bad. Could be our calibration accuracy is wrong, or our uncertainty calculation is wrong or our oil bath went kaput – but something is amiss because if we have everything correct then the results should reflect the theoretical model.
Eli understands and assumes that everyone knows this. P.F. in his #’s 11 and 12 clearly shows that he does not.
I ran into this problem with the very first large-scale project I put together several decades ago. My results were inconsistently twice as bad as I expected them to be (i.e., the uncertainties were twice as large as I wanted them to be). I poured over the uncertainty calculations for hours trying to find an error, but couldn’t. I pushed the problem off to the side while I worked on other parts of the project, and then one day I was describing the problem to a retired engineer who was doing some consulting and he laughed and told me there was probably nothing wrong with my calculations, but that I was making the measurement incorrectly. He was correct. I made a slight adjustment to the measurement process and all the numbers fell into line. Math works.
20 people, total height 30 meters. Is that average height = 30 meters/ 20 people = 1.5 meters/person.
Or is it 30 meters/20 samples = 1.5 meters/sample.
I’m going to lie awake tonight worrying about this…..
Simple experiment: use the model to generate a century or so of synthetic data with some set of parameters, theta. Next get another climate modeller to try and predict the first model run, but without knowing the true values of the model parameters. Say the second modeller has a luck guess at the parameters, theta’, which is identical to theta, except that long wave cloud forcing is out by 4Wm-2. Pat’s argument would also apply to that and suggest that the “statistical uncertainty” in the predictions would diverge. Of course this is obviously incorrect, the model predictions would converge to a slightly different equilibrium temperature, but the spread of the model runs wouln’t be greatly different.
angech,
Except it’s not random; it’s constrained by energy balance. So, as Eli has pointed out (and EFS in the comment before you) it can’t drift randomly away from equilibrium, there is a limit to have from equilibrium it can go.
Kevin said:
I wouldn’t doubt that. Kevin has got such a dogged determination and doesn’t pull any punches when something is not right. Thanks!
Nicely phrased. I may reuse/steal this in future, Kevin.
“Except it’s not random; it’s constrained by energy balance. So, as Eli has pointed out (and EFS in the comment before you) it can’t drift randomly away from equilibrium, there is a limit to have from equilibrium it can go.”
–
ATTP, I agree with you, Eli agrees with you, the natural variation is constrained by the energy balance.
It’s not random.
Here is a problem.
Being a natural variation it is random within a limiting framework.
This constraint makes it non random in only one sense, There is a boundary on either side that it can hit but not go beyond, if the boundary, the energy balance is real and fully known.
But within the limits of the boundary it is functionally random.
Hence deviations can propagate to the limitations of the boundary.
–
Hence a comment by Kevin O’Neill . When answers do not align with reality do a spot check on all your inputs.
In maths with multiplication in the head one might get an error a couple of magnitudes out when in a hurry. A simple check of the magnitudes involved in the initial units added together might show that your sum is way out of line.
–
PF’s spread mathematically alright, so ask re the maths used.
One simple answer may be that the natural variation in a constrained situation behaves differently as it approaches the boundary condition and becomes much smaller on the outer edge. This would reduce the cone of uncertainty somewhat.
I would assume that this is known and factored in though?
–
Nonetheless DM agrees with me
“the model predictions would converge to a slightly different equilibrium temperature, but the spread of the model runs wouldn’t be greatly different.”
when I said
“No matter the divergence,as long as it is random and around a mean variance, the end result as the number of years increased would be spaghetti with the largest number of results still centred around the mean. Strongly converging would be the mathematical term for the overall result.”
He would agree with
“Wildly diverging would only apply to the much, much smaller number of results that diverge in opposite directions from the mean”
perhaps if I added another much or two.
WHUT writes: “…doesn’t pull any punches when something is not right”
Yes, my lack of tact has been noted before. Guilty as charged 🙂
I don’t take criticism of work-product personally – nor do I expect it to be received as such. If I was able to be of any assistance then you’re more than welcome. I’ve enjoyed working with the ENSO model you’ve put together and only wish I were going to be around long enough to see it receive widespread acceptance and the beneficial effects it will have on GCM projections when they begin to incorporate the deterministic properties of ENSO that you’ve revealed.
Kevin, Your input has been valuable. It really is about getting it right. Thanks
angech wrote “Being a natural variation it is random within a limiting framework.”
No, it is chaotic, which is not the same thing (i.e. deterministic, but sensitive to initial conditions),
“This would reduce the cone of uncertainty somewhat.
I would assume that this is known and factored in though?”
It isn’t a cone though, that is the point, it is a constant width cylinder (once the model has “burned in”)
“Nonetheless DM agrees with me”
I don’t think I do, see above.
“He would agree with”
I have asked you not to do that before, if you want me to agree to something, then ask me. Assuming you know what someone thinks is not very polite, especially when you are wrong.
An example of what can happen as a result of pal-review
(if your pals are really good pals ;o)
At the time Kevin wrote this, he and I knew he only had a few months left. I couldn’t believe that he spent so much time helping out with the ENSO model, and he may have been working on it up until he passed away last week.
I think many people have seen Keith’s comments here and on other climate blogs over the years. He helped the cause via his expertise in metrology. Keith was a thorn in the side of Steve McIntyre, Judith Curry and other denialists
RIP
Sorry to hear about Kevin O’Neill. Condolences.
Appreciate that.
Another scientist that has been helping out immensely with the ENSO model, and who has contributed to this blog and others is Keith Pickering. He died in a tragic car accident a couple months ago. Anything to do with difficult subjects like astrophysics and nuclear energy, he was willing to wade in.
I will make sure to include them in acknowledgements. These two guys were the most ideal supporters anyone could wish for. They were enthusiastic but tough in terms of supplying a critical eye.